Starting Your Machine Learning Odyssey: A Comprehensive Guide
A Beginner's Guide to get started with Machine Learning

Machine learning (ML) is an exciting field that allows computers to learn and make predictions or decisions without special programming. As a beginner, diving into ML can seem daunting, but with the right approach and tools, it can transform into an exciting journey. In this blog, we introduce you to the world of ML and provide a roadmap for your learning.
What is Machine Learning?
Machine Learning is a subset of artificial intelligence (AI) that focuses on the development of algorithms and statistical models to enable computers to improve their performance on a specific task through experience. In essence, it's about teaching machines to learn from data and make intelligent decisions based on that learning.

Getting Started with Machine Learning as a Beginner

Core Concepts
Machine Learning, as a field, is built upon several fundamental concepts that serve as the building blocks for understanding and working with ML algorithms and models.

As a beginner, it's crucial to grasp these core concepts, which can be broadly categorized into three main types:
1. Supervised Learning:
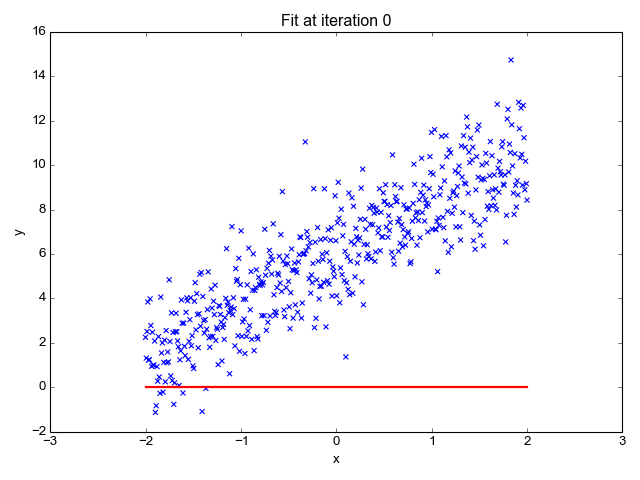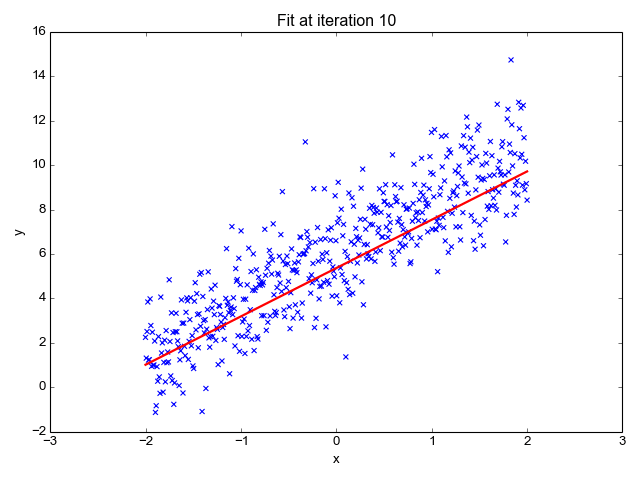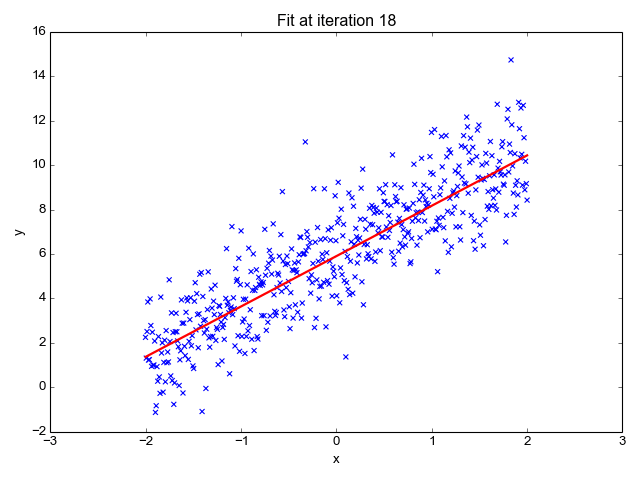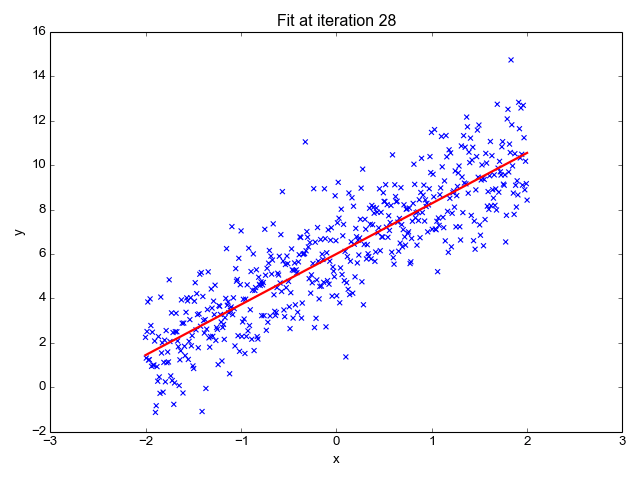
Regression: Regression is a type of supervised learning where the goal is to predict a continuous numerical value. You'll learn how to build models that can make predictions like house prices, stock prices, or temperature based on historical data.
Classification: Classification is another type of supervised learning where the goal is to assign data points to predefined categories or classes. You'll explore techniques to build models for tasks such as spam email detection, sentiment analysis, or image classification.
2. Unsupervised Learning:
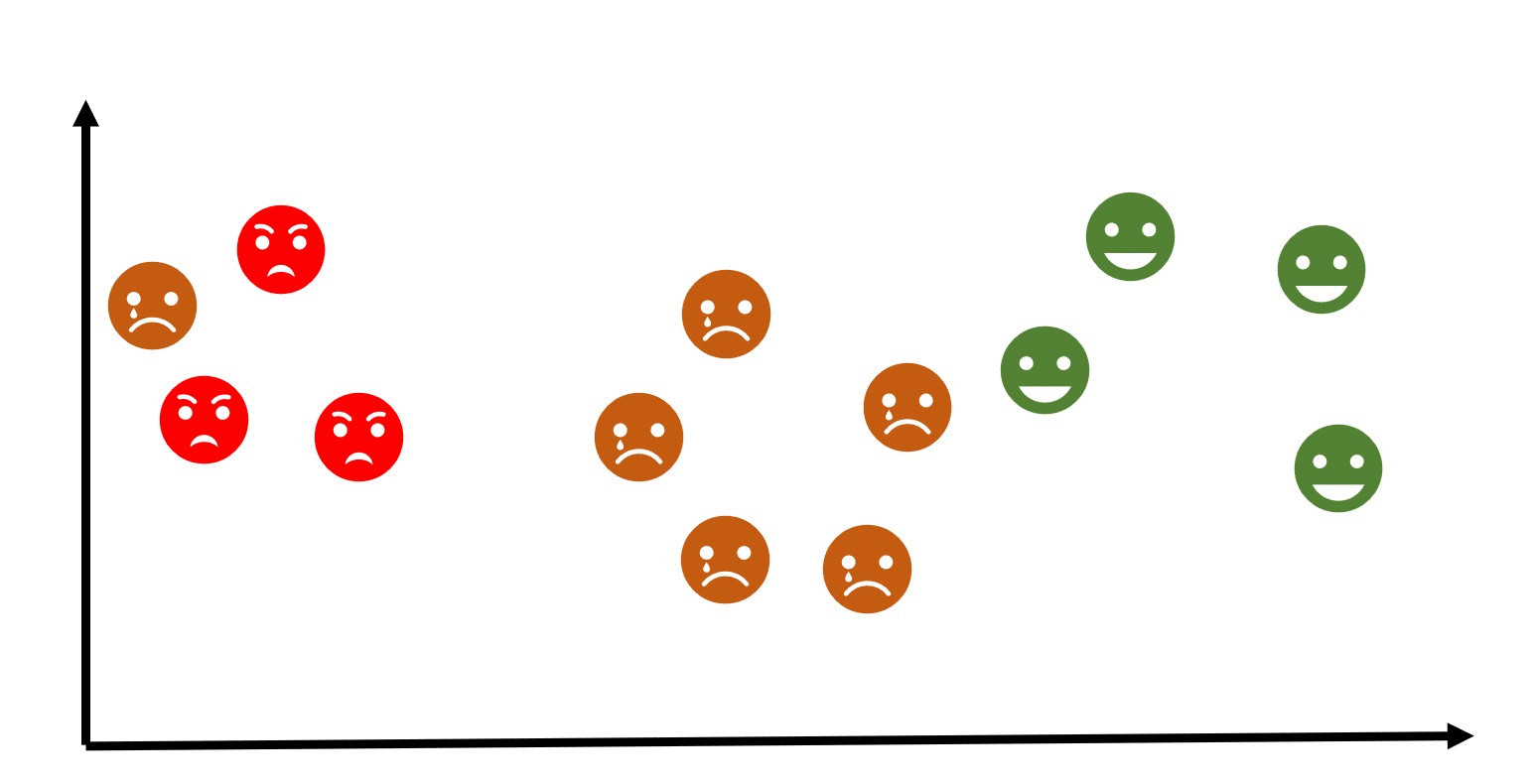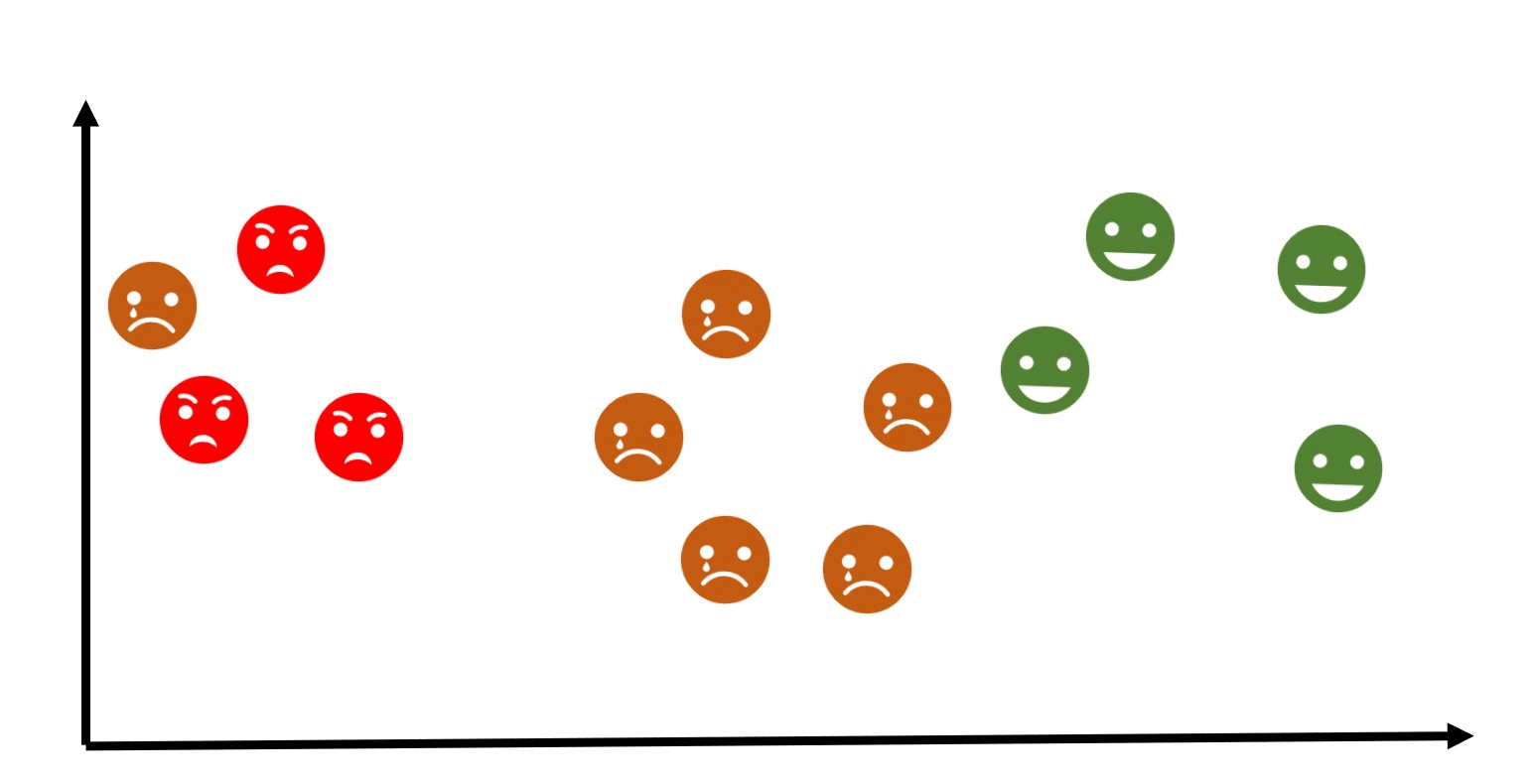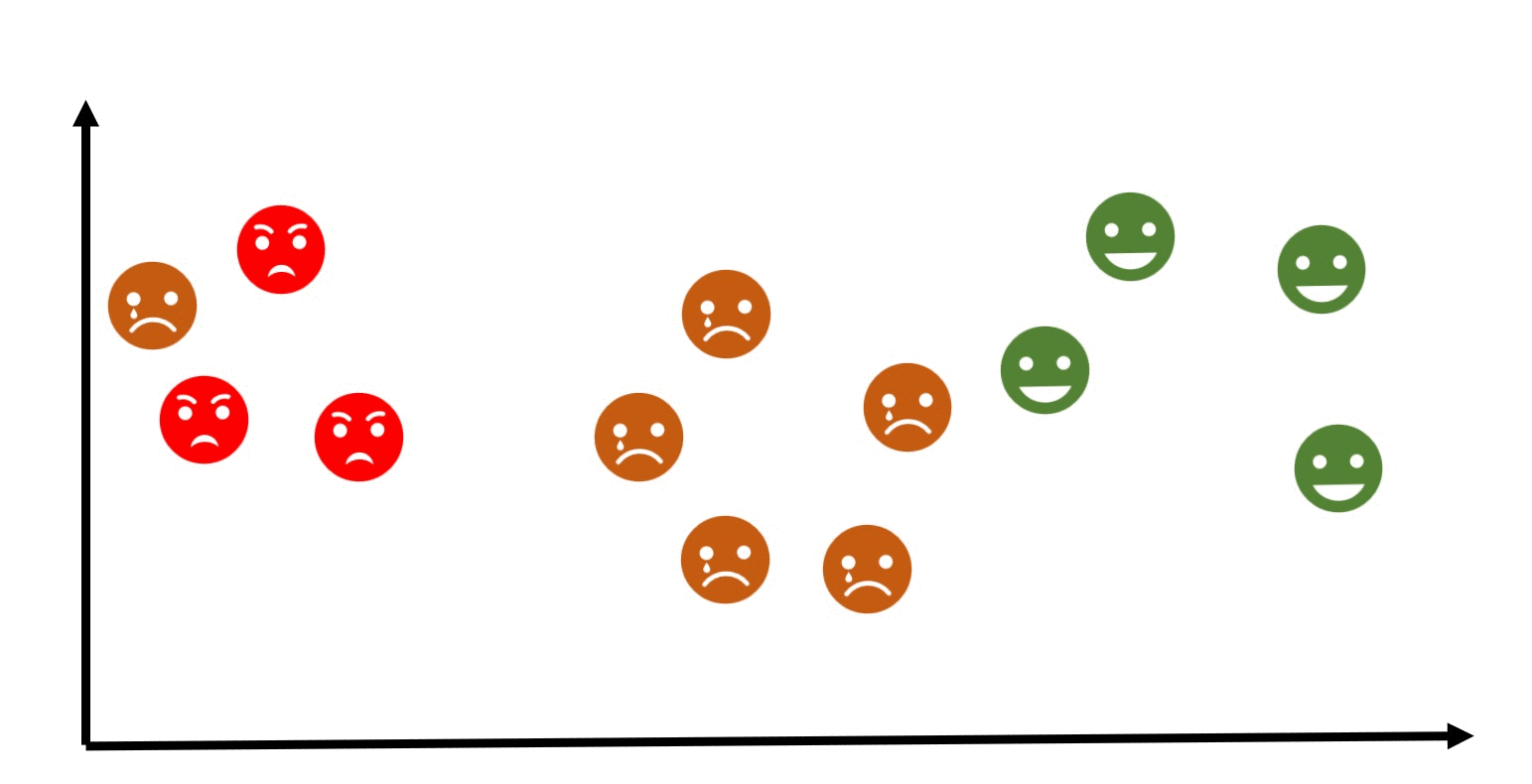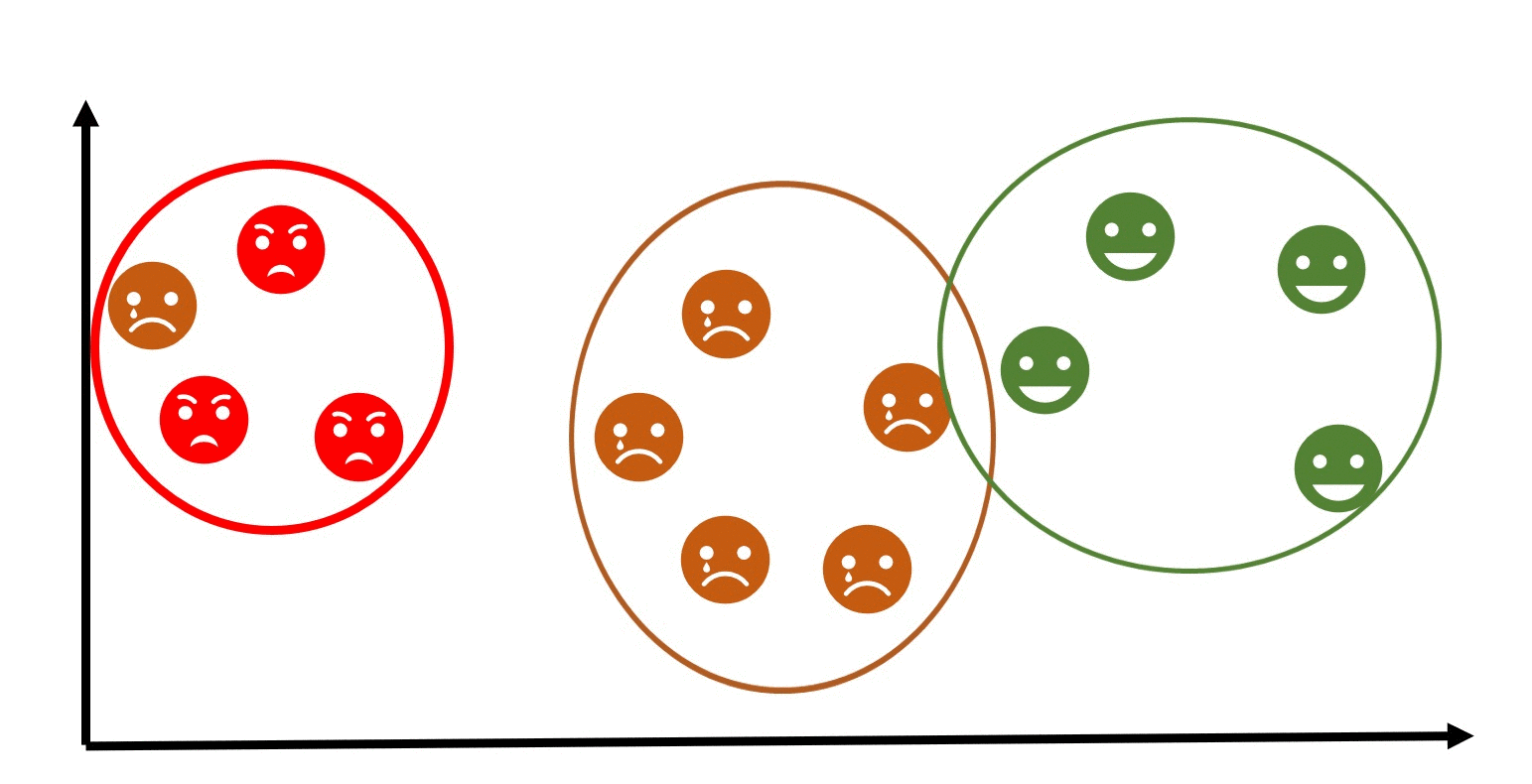
Clustering: Unsupervised learning includes clustering algorithms that group similar data points based on some similarity measure. You'll understand how to apply clustering to segment customer data, group news articles, or identify anomalies in data.
Dimensionality Reduction: Dimensionality reduction techniques aim to reduce the number of features in a dataset while preserving its essential information. Principal Component Analysis (PCA) is a widely used technique for this purpose.
3. Deep Learning:
Neural Networks: Neural networks are at the heart of deep learning. You'll delve into the architecture and workings of artificial neural networks, which are inspired by the human brain. These networks are used for complex tasks like image recognition, natural language processing, and more.
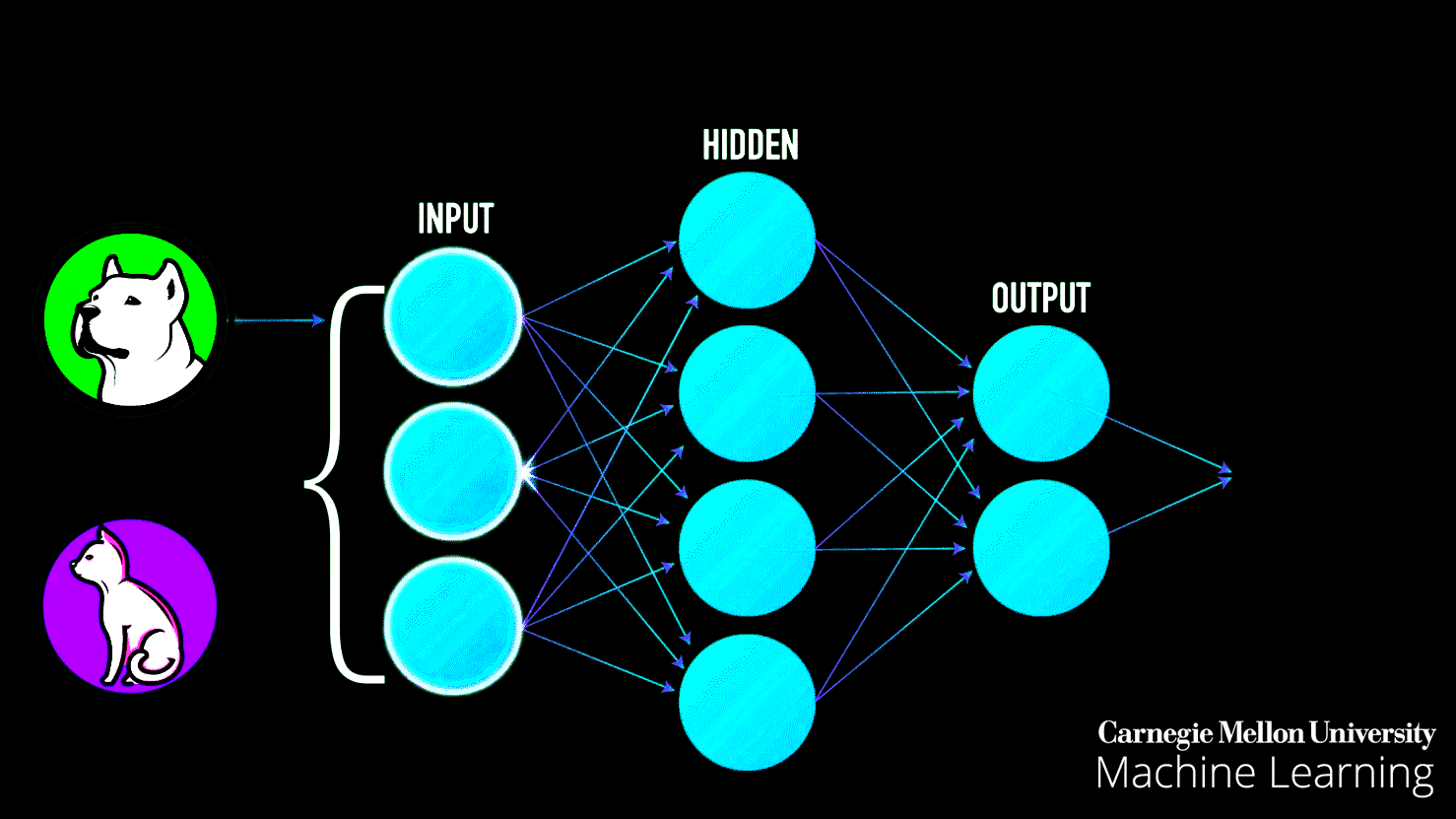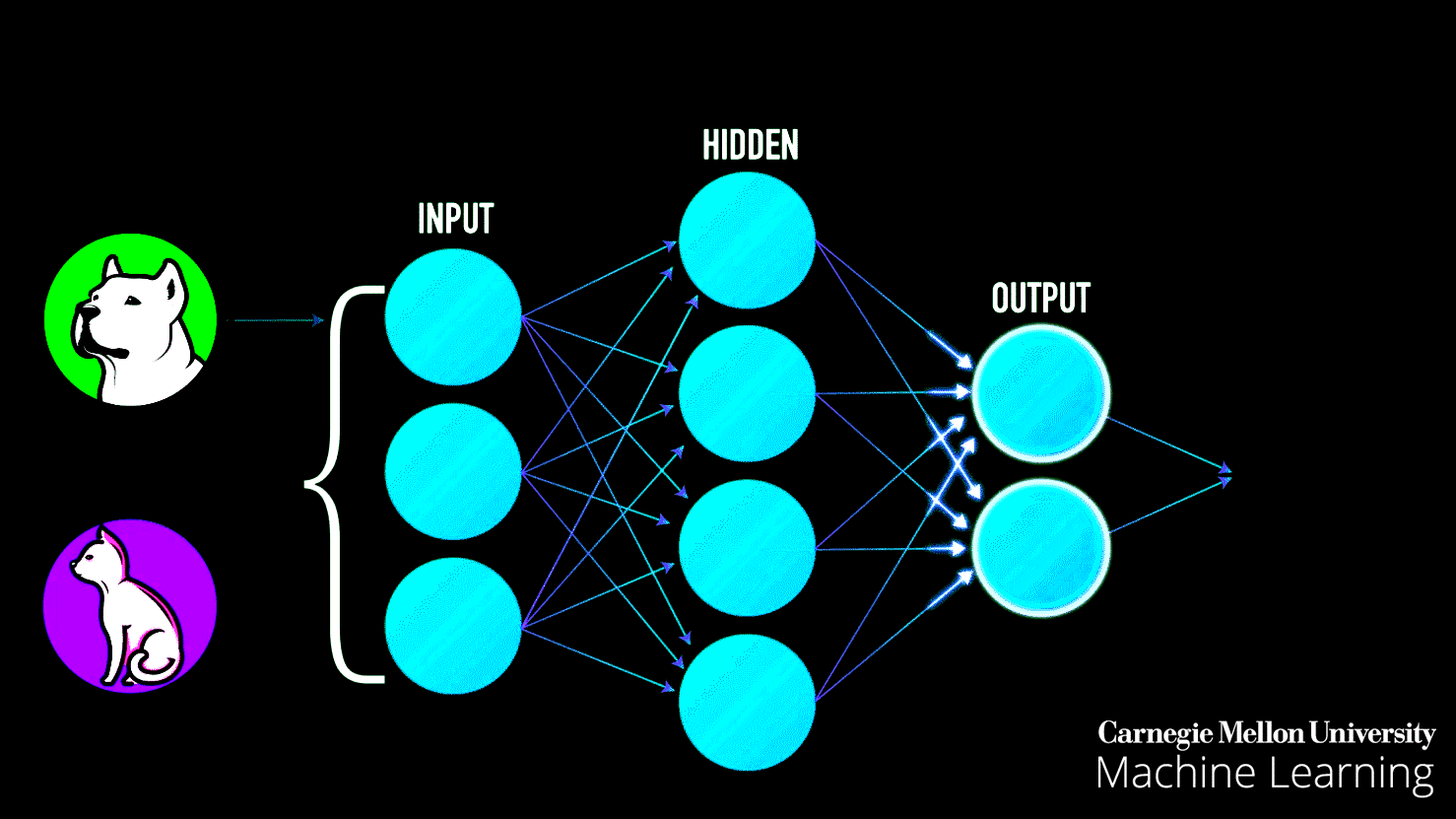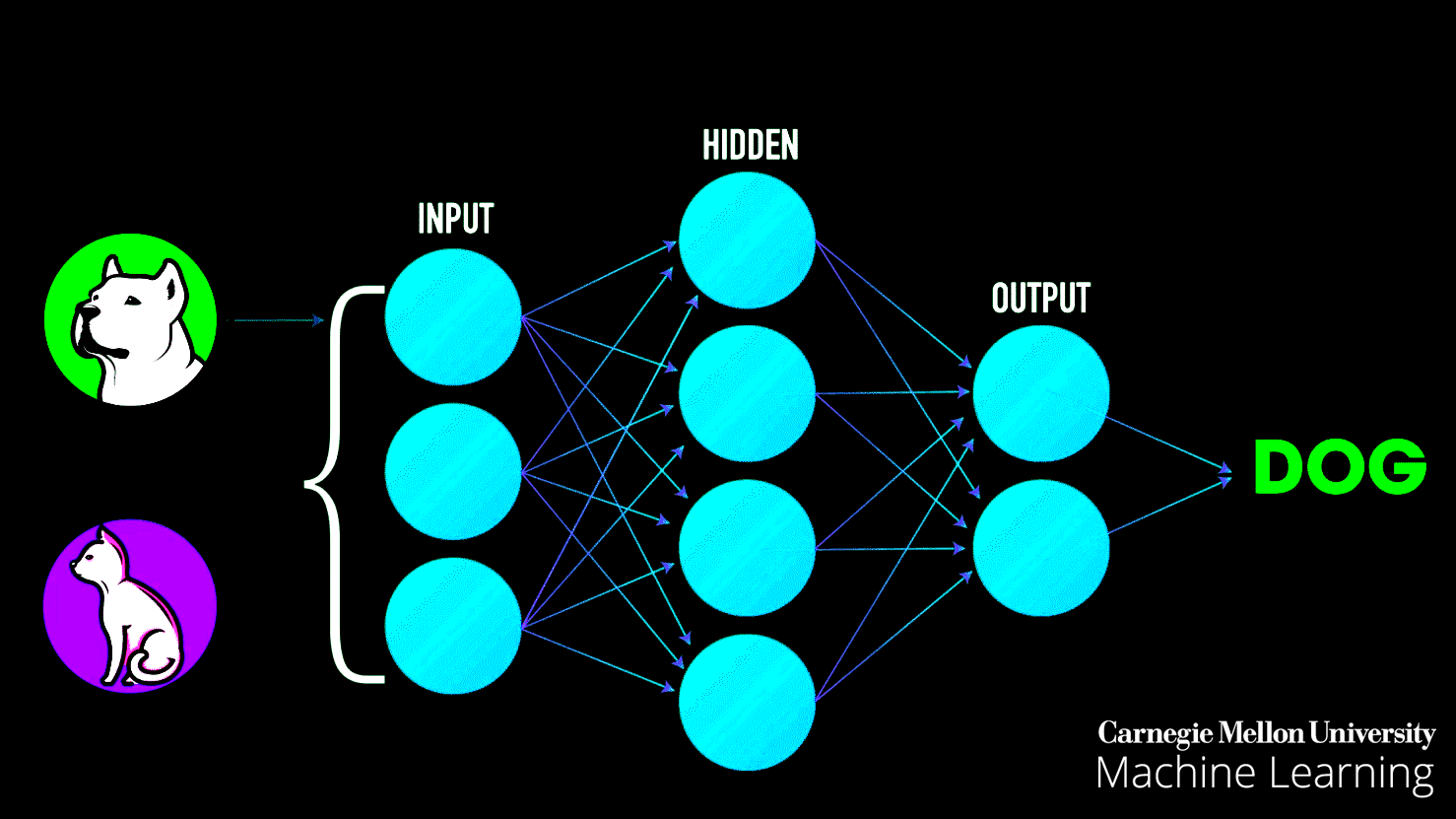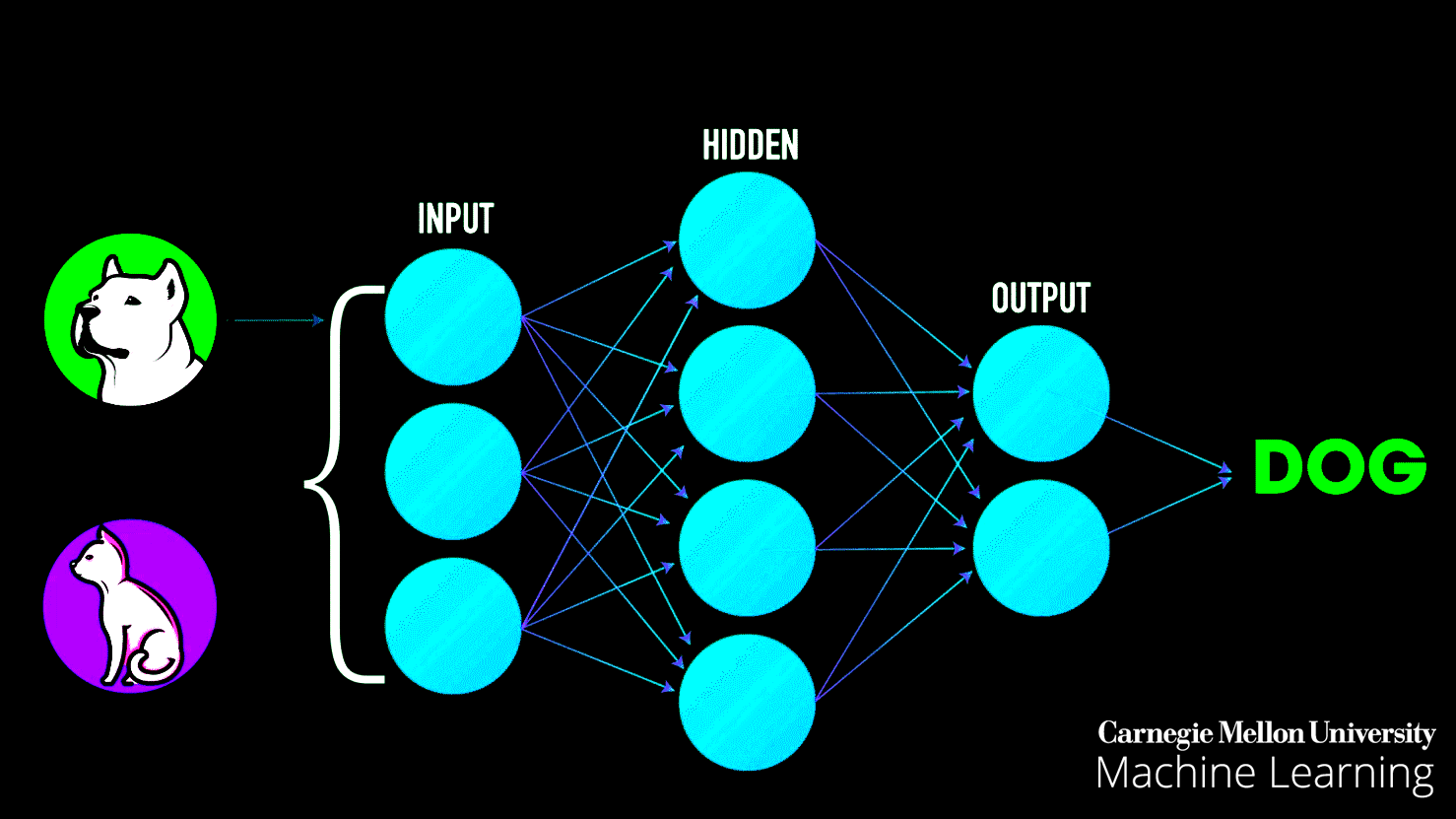
Building a strong foundation in these fundamentals will enable you to tackle more advanced machine-learning topics and projects as you progress in your learning journey.
Languages
Python is the go-to programming language for machine learning, and there are several compelling reasons for its popularity:
Ease of Learning: Python's simple and readable syntax makes it an ideal choice for beginners. You don't need to be a seasoned programmer to get started with Python.
Vast Ecosystem: Python boasts a rich ecosystem of libraries and frameworks that are specifically designed for machine learning and data science. Some of the most prominent ones include:
NumPy: For numerical operations and handling arrays and matrices.
Pandas: For data manipulation and analysis.
Scikit-Learn: A versatile library containing a wide range of machine learning algorithms.
TensorFlow and PyTorch: Leading deep learning frameworks used for building neural networks.
Cross-Platform Compatibility: Python is compatible with various operating systems, including Windows, macOS, and Linux, making it accessible to a broad audience.
Integration: Python can be seamlessly integrated with other technologies and tools commonly used in machine learning, such as Jupyter Notebooks for interactive coding and data visualization libraries like Matplotlib and Seaborn.

Mathematics:
Dive into the math behind ML:
Linear Algebra: Vectors, matrices, and operations.
Calculus: Derivatives and gradients.
Statistics: Probability, distributions, and hypothesis testing.
1. Linear Algebra:
Vectors and Matrices: Linear algebra forms the foundation of many Machine Learning algorithms. Vectors and matrices are used to represent data and transformations.
Matrix Operations: You'll encounter operations like matrix multiplication, addition, and transposition when working with datasets and model parameters.
Eigenvalues and Eigenvectors: These concepts are essential in techniques like Principal Component Analysis (PCA) used for dimensionality reduction.
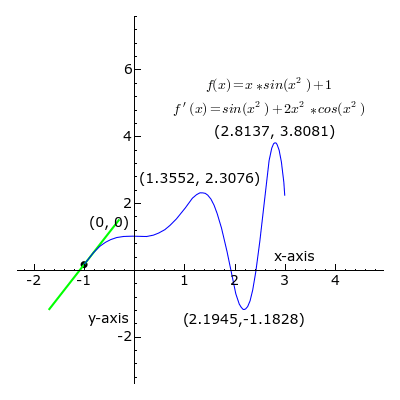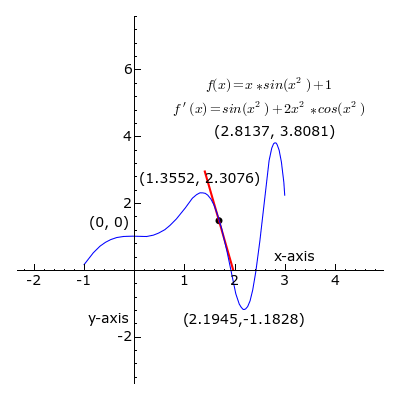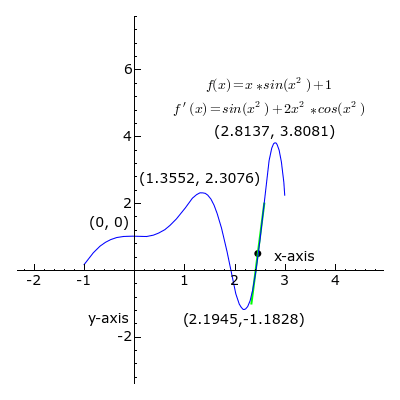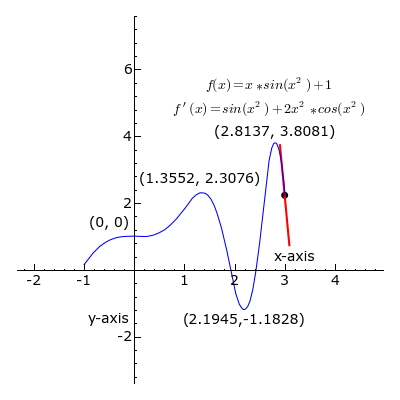
2. Calculus:
Derivatives: Calculus helps in understanding the slope or rate of change. In Machine Learning, derivatives are crucial for optimization algorithms like gradient descent, used to train models.
Gradients: Gradients represent the direction and magnitude of the steepest ascent in a function. They are used to update model parameters iteratively during training.
3. Statistics:
Probability: Probability theory is used to model uncertainty in data and make probabilistic predictions. It's fundamental for algorithms like Naive Bayes and Hidden Markov Models.
Distributions: Understanding probability distributions such as Gaussian (normal) distribution is essential for modeling and analyzing data.
Hypothesis Testing: Statistical tests help validate hypotheses and make informed decisions based on data.

4. Linear Regression and Least Squares:
Linear Regression: It's a foundational supervised learning technique. The mathematics behind linear regression involves minimizing the sum of squared differences between the predicted and actual values.
Least Squares: This method finds the best-fitting line through a dataset by minimizing the sum of the squares of the residuals (the differences between observed and predicted values).
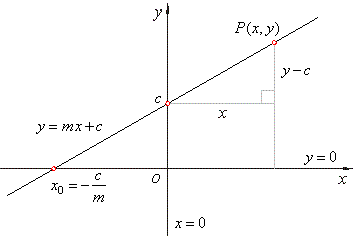
These mathematical concepts are just the tip of the iceberg. As you delve deeper into Machine Learning, you'll encounter more advanced mathematics, including multivariate calculus for deep learning, optimization techniques, statistical inference, and more.

Algorithms
In the context of machine learning, an algorithm is a set of rules and statistical methods that a computer uses to learn patterns and make predictions or decisions from data. Understanding and implementing these algorithms are crucial for any aspiring machine-learning practitioner. Here are some fundamental machine learning algorithms you should focus on as a beginner:
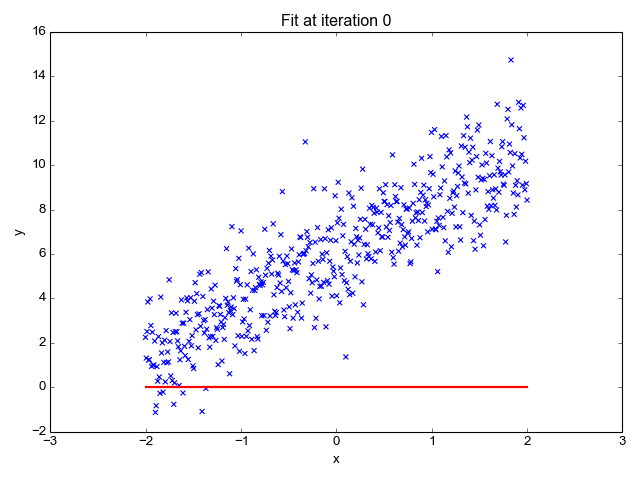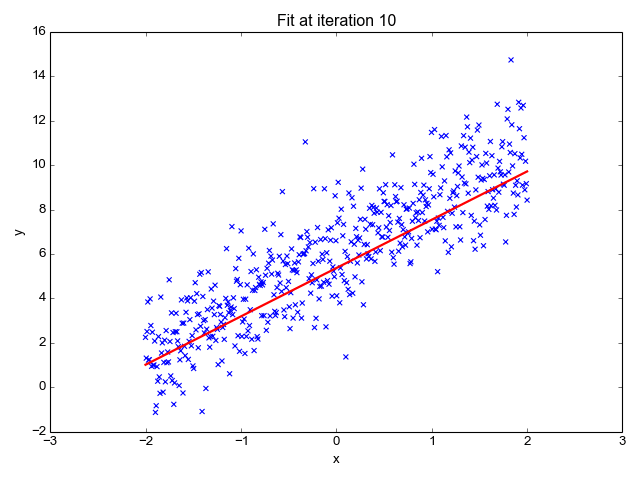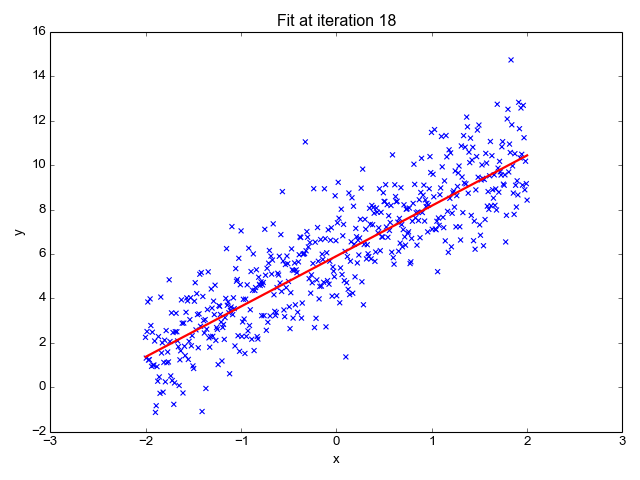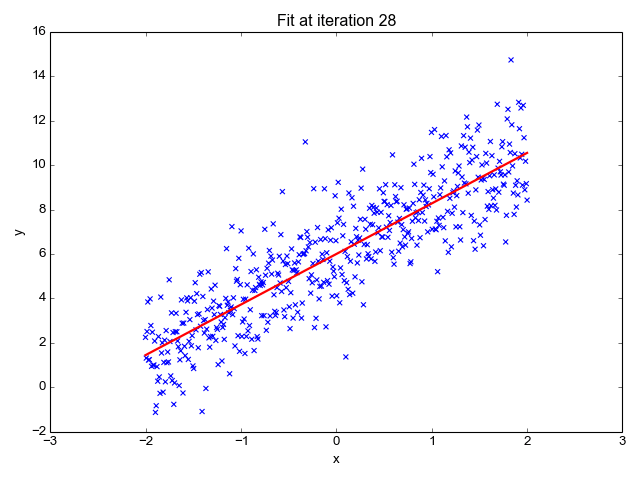
1. Linear Regression:
Linear regression is used for predicting a continuous outcome variable (dependent variable) based on one or more predictor variables (independent variables). It's a foundational algorithm for understanding the concept of supervised learning.
2. Logistic Regression:
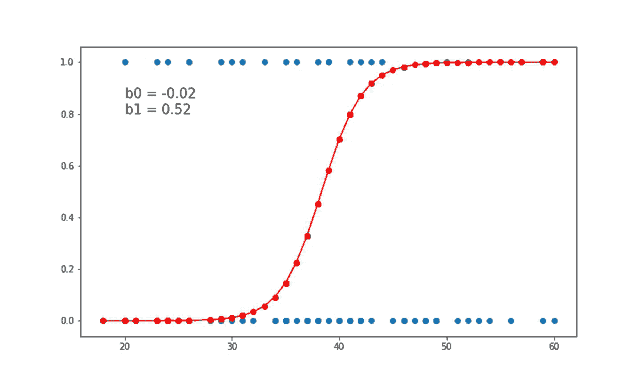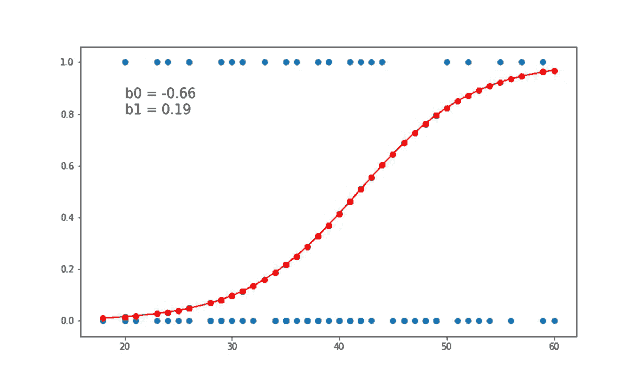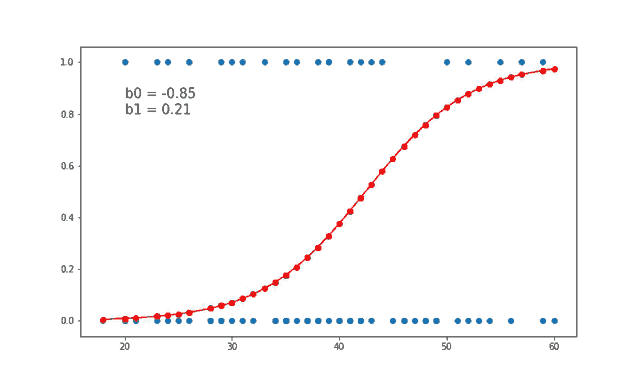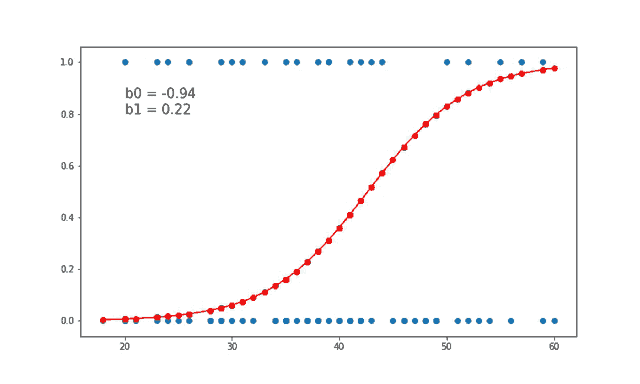
Logistic regression is another supervised learning algorithm, but it's used for binary classification problems. It predicts the probability of an example belonging to a particular class.
3. Decision Trees:
Decision trees are versatile algorithms used for both classification and regression tasks. They break down a dataset into smaller subsets based on various criteria to make predictions.
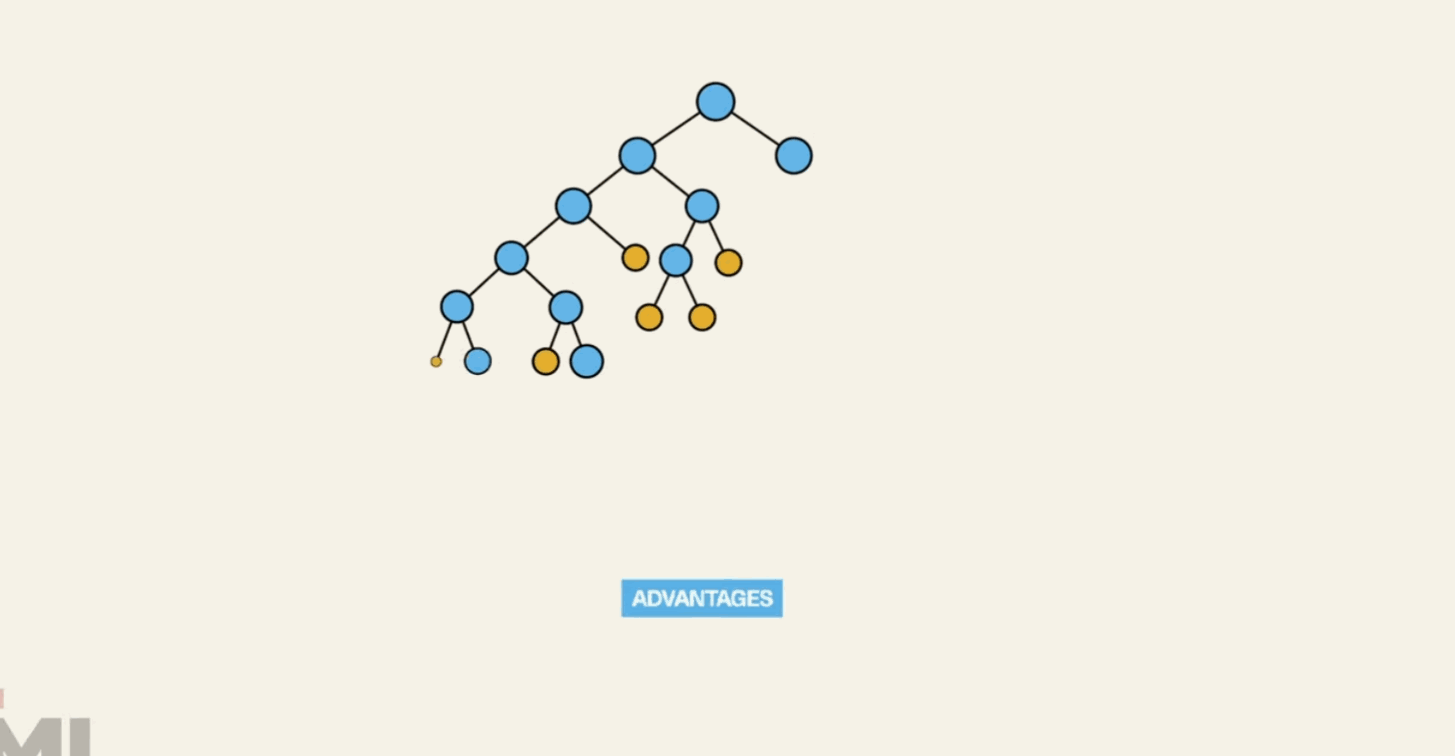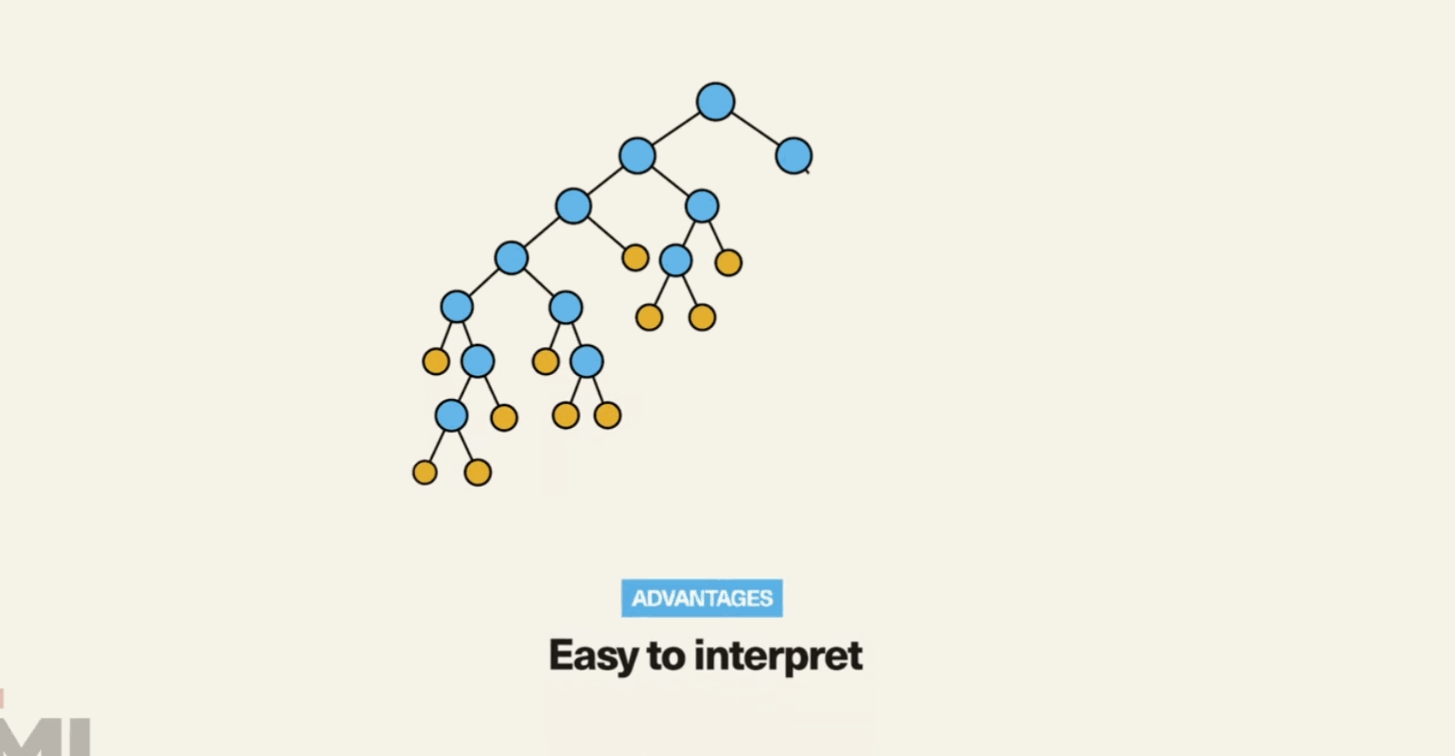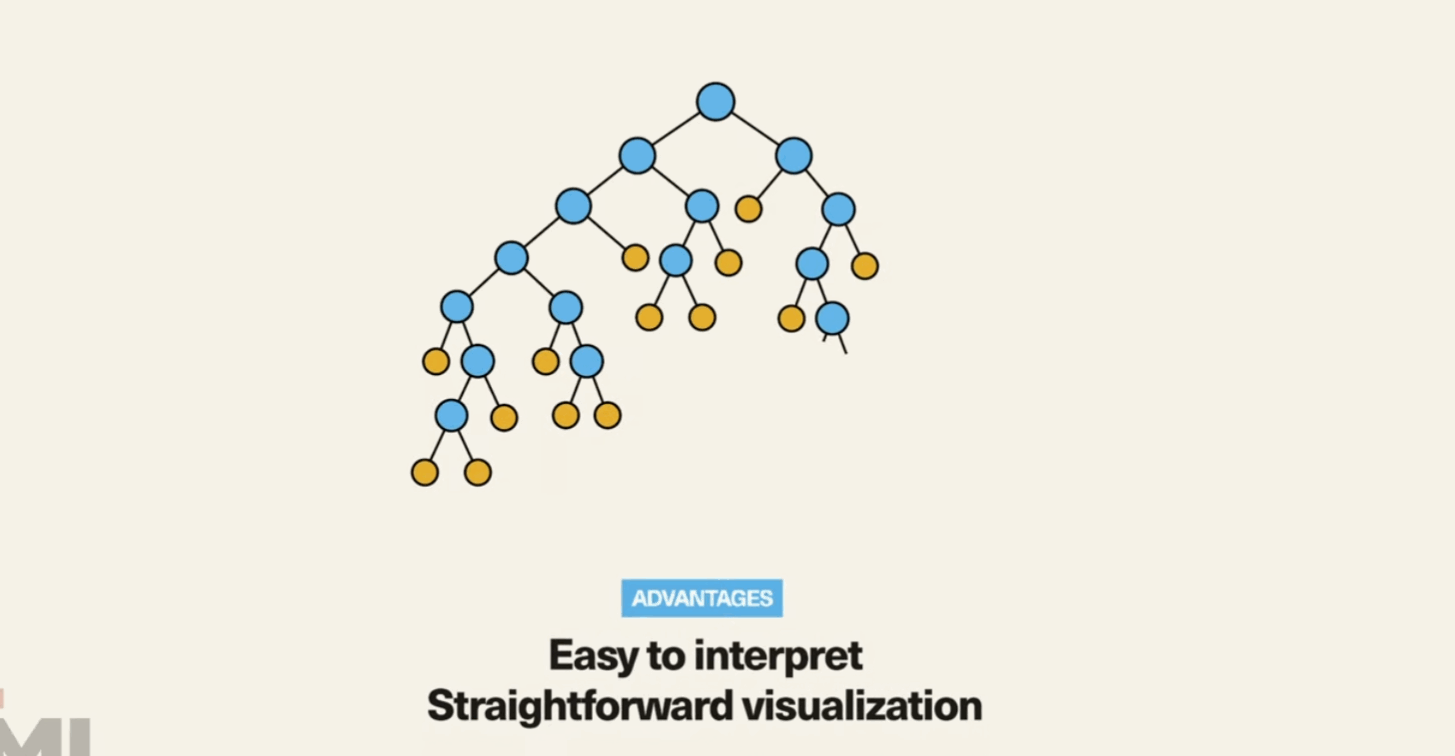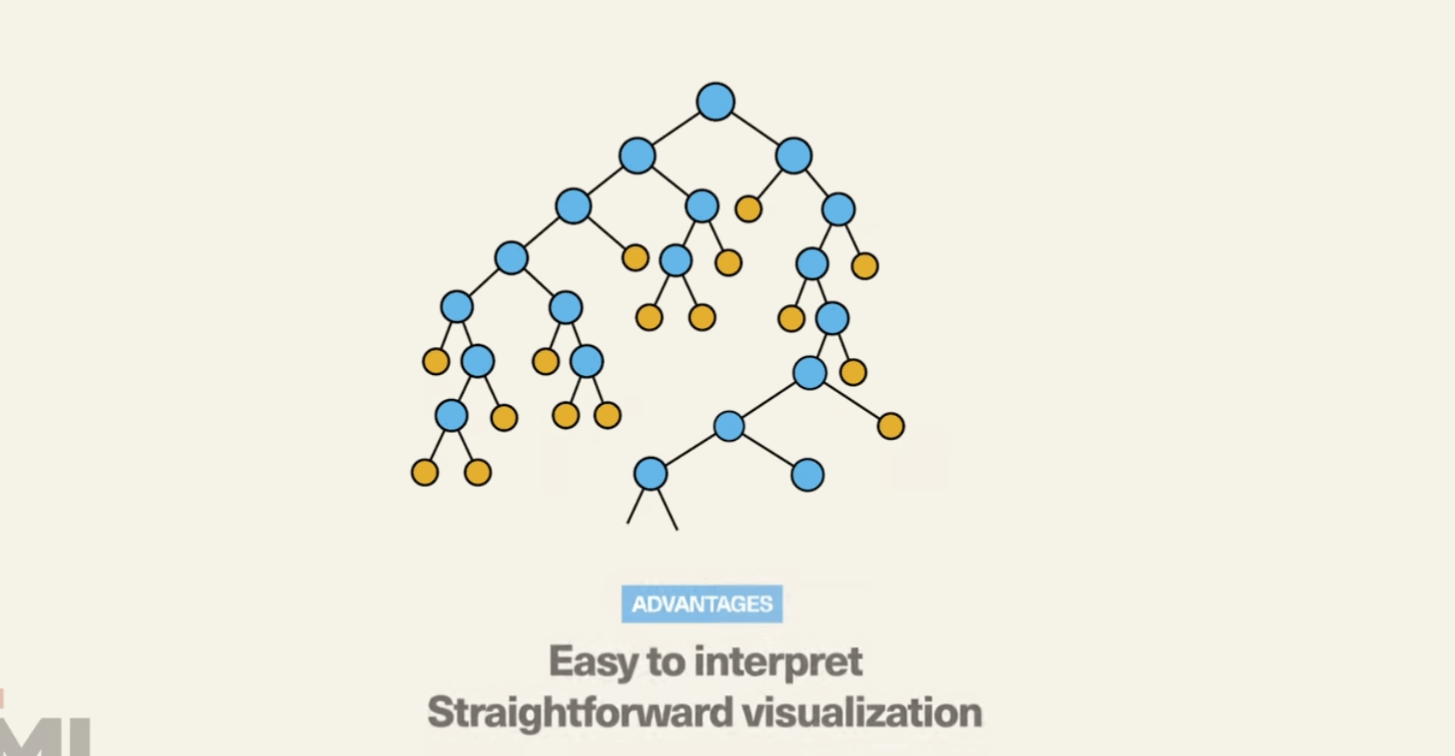
4. Random Forests:
Random forests are an ensemble learning technique built on decision trees. They improve prediction accuracy by combining the results of multiple decision trees.
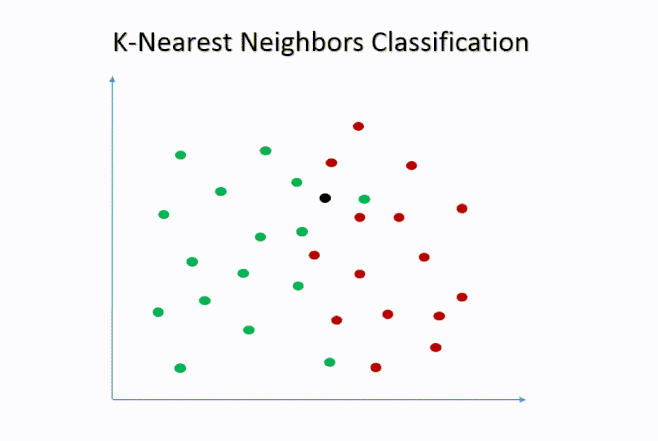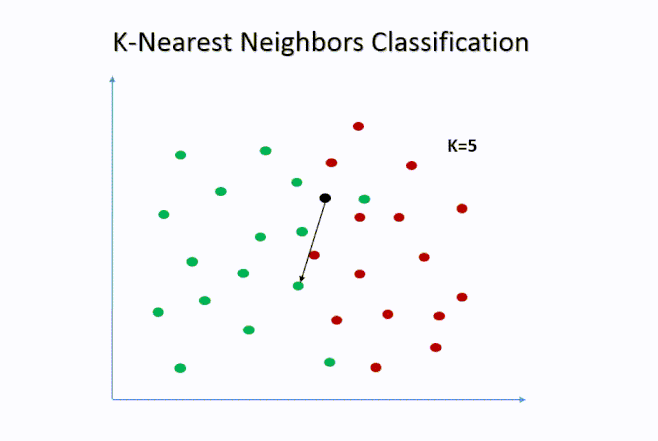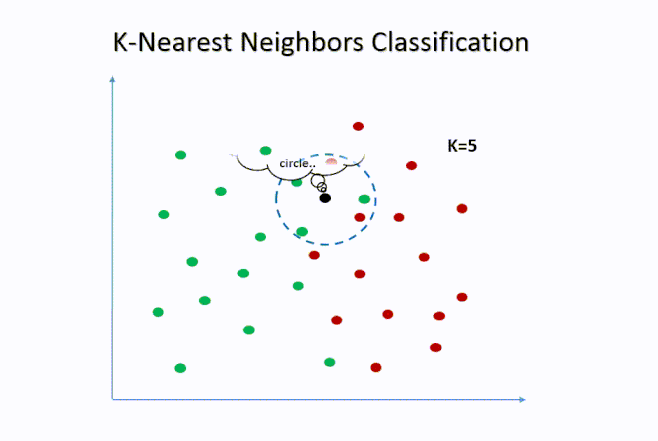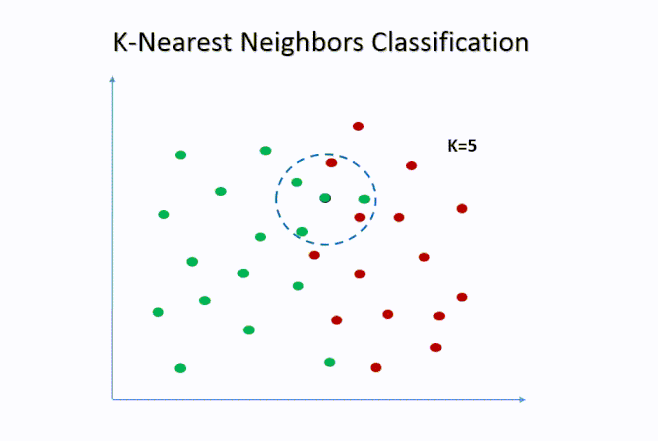
5. K-Nearest Neighbors (K-NN):
K-NN is a simple but powerful algorithm for both classification and regression. It predicts the class or value of a data point based on the majority class or average value of its nearest neighbors.
6. Naive Bayes:
Naive Bayes is a probabilistic algorithm used for classification problems. It's particularly popular in natural language processing (NLP) applications like spam email detection.
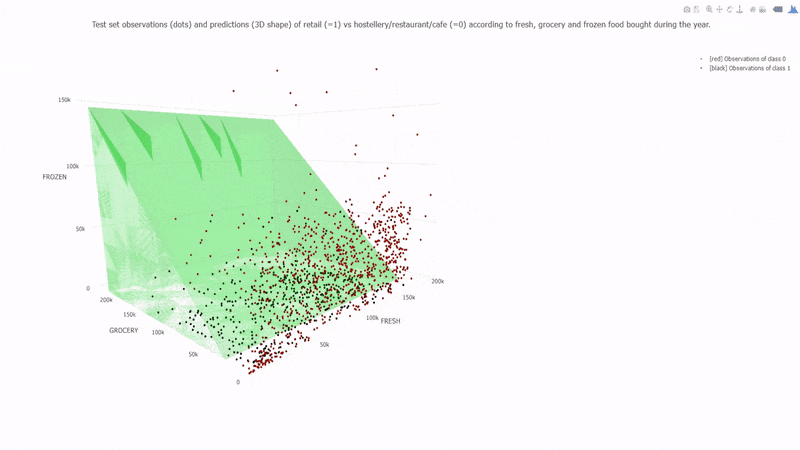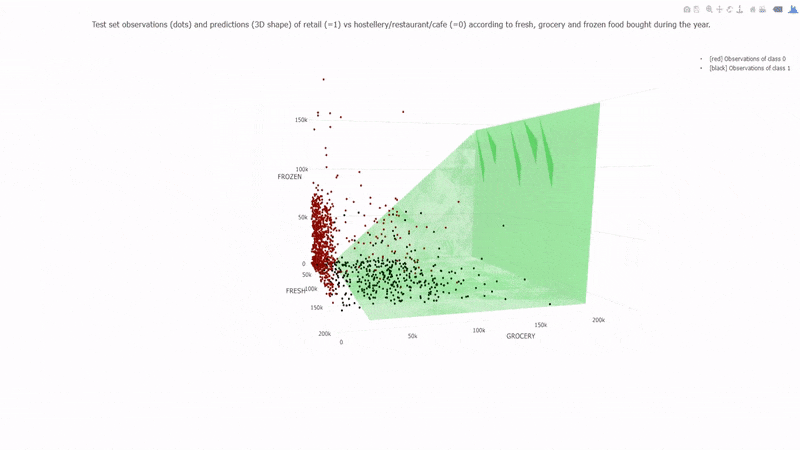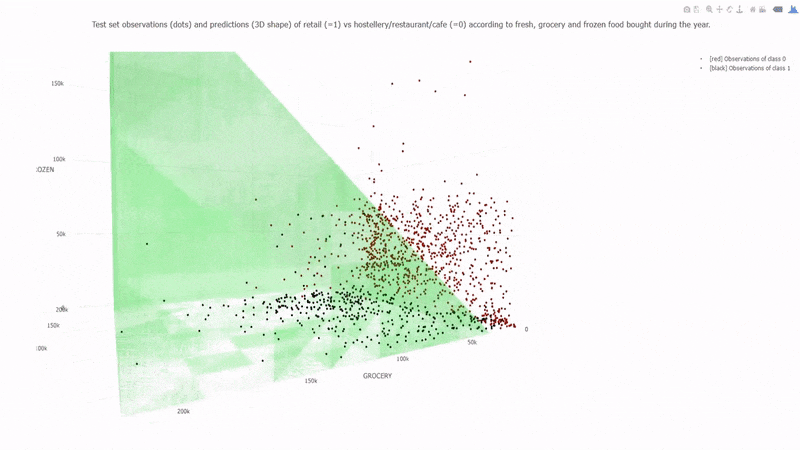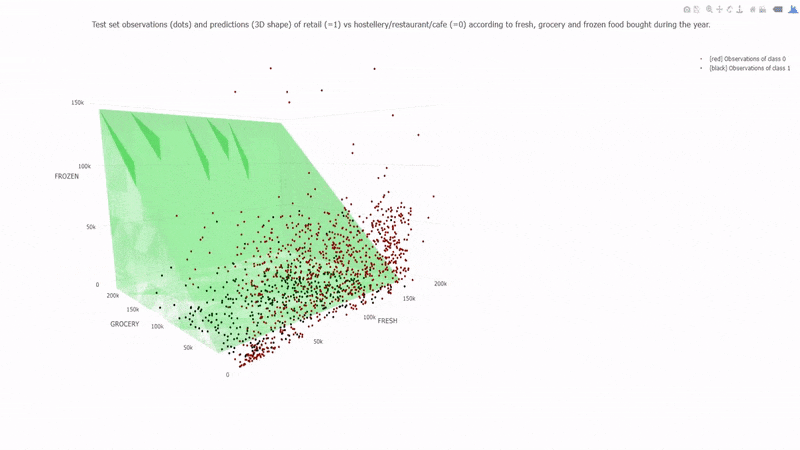
7. Support Vector Machines (SVM):
SVM is a versatile algorithm used for classification and regression tasks. It finds a hyperplane that best separates data into different classes.
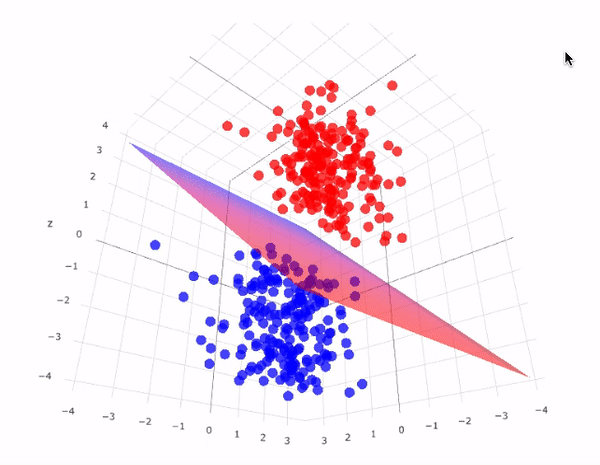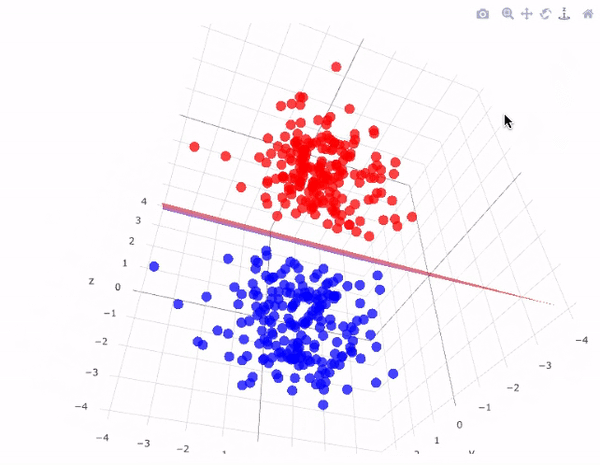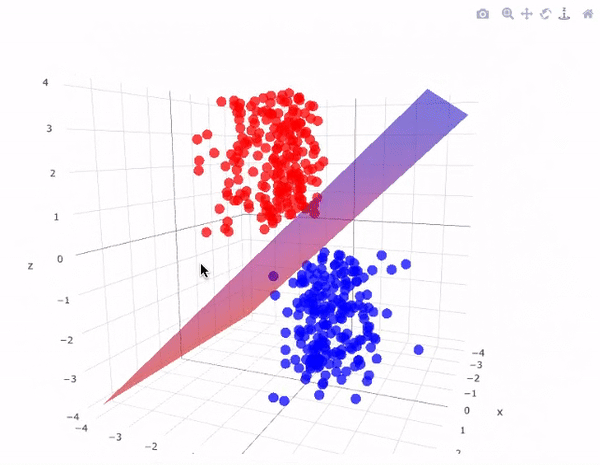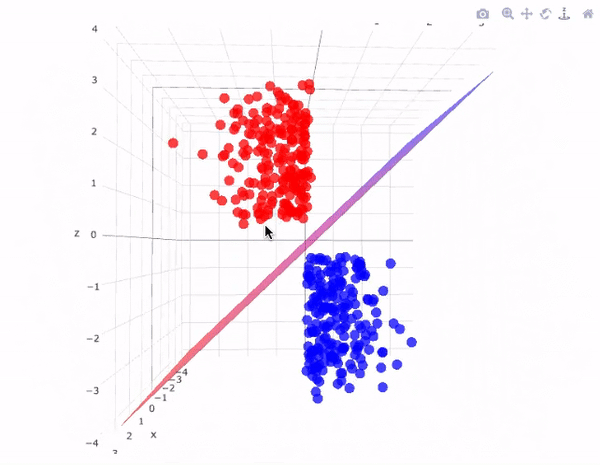
Each of these algorithms has its strengths and weaknesses and is suited to different types of problems. As a beginner, it's essential to understand the underlying principles, mathematics, and practical implementation of these algorithms. You'll use them as foundational tools in your machine-learning projects and experiments.

Deep Learning
Deep Learning is a subset of Machine Learning that has gained immense popularity and success in various applications, including image and speech recognition, natural language processing, and autonomous driving. Deep Learning models, often called neural networks, are designed to mimic the way the human brain processes information.
Key Concepts in Deep Learning:
a. Feedforward Neural Networks:
Explanation: These are the basic building blocks of deep learning. They consist of an input layer, one or more hidden layers, and an output layer. Each layer contains neurons that process and transform the input data.
Application: Feedforward Neural Networks are used for tasks like image classification and regression.
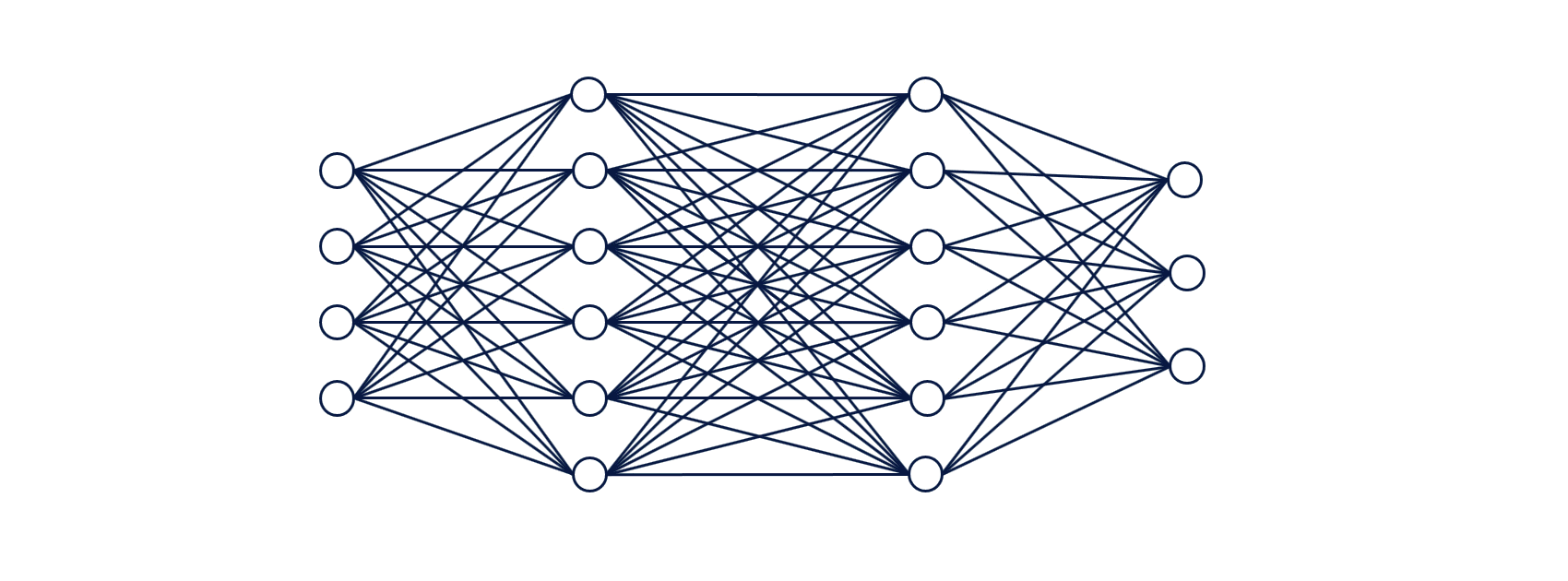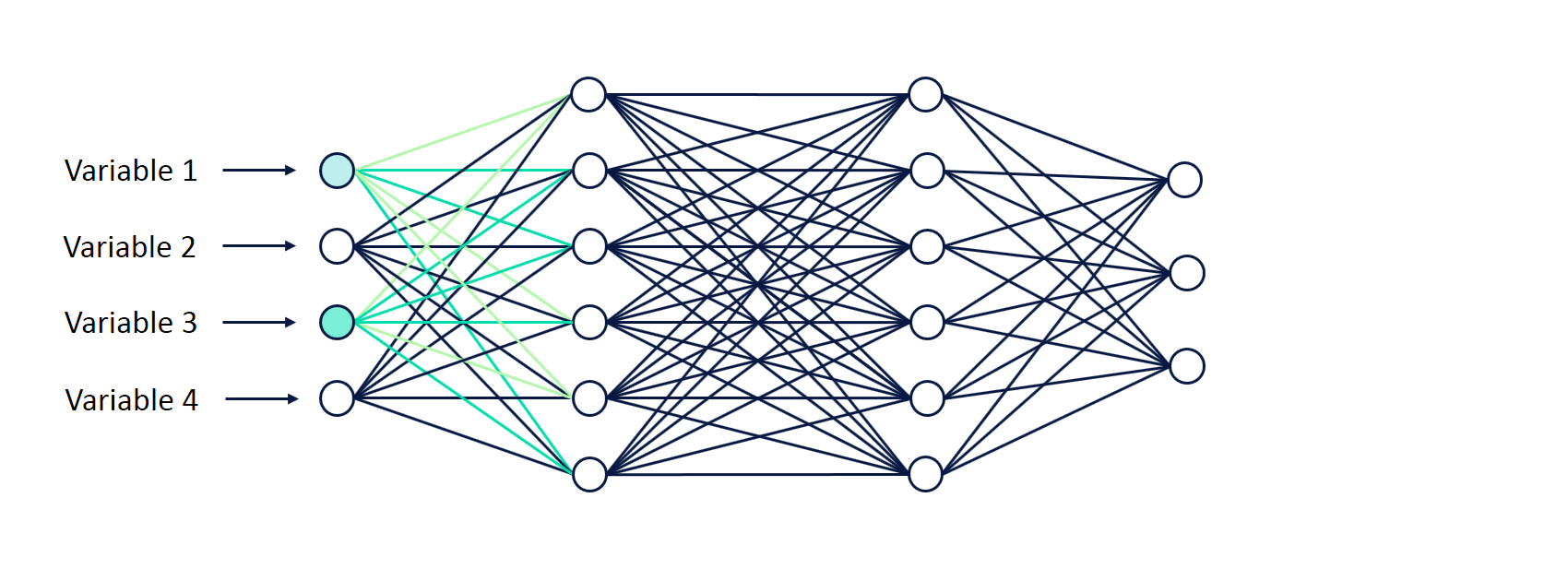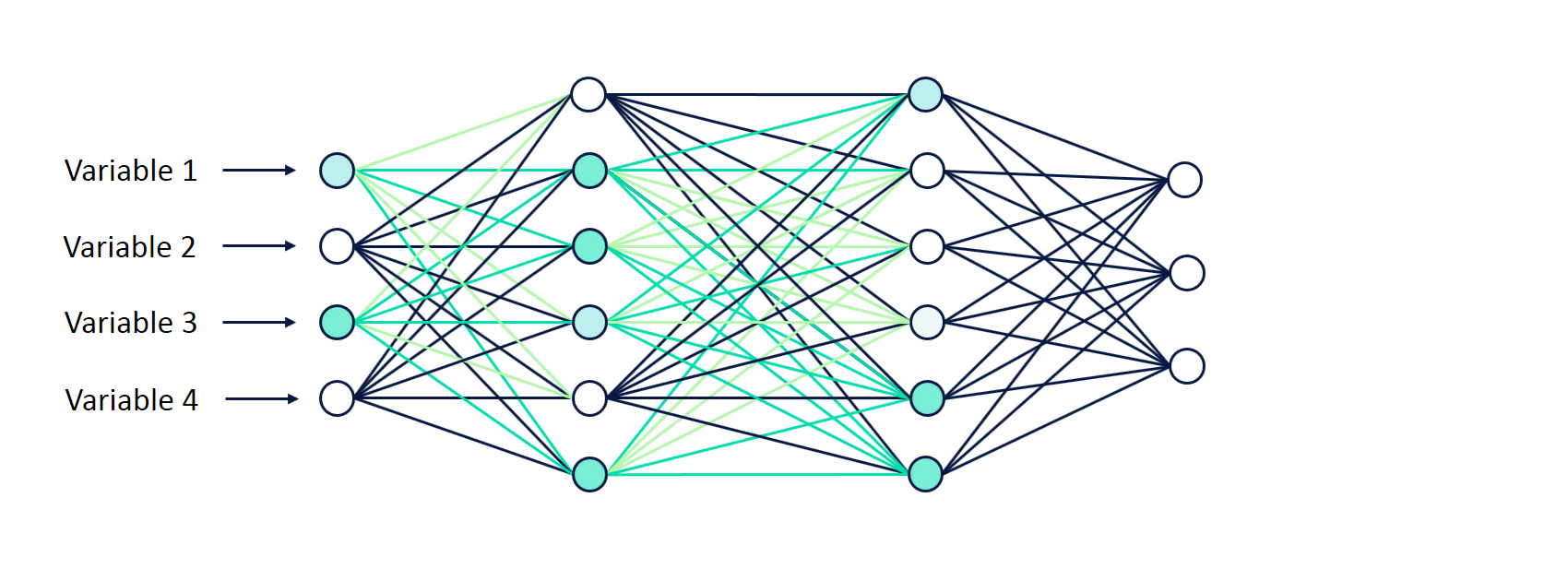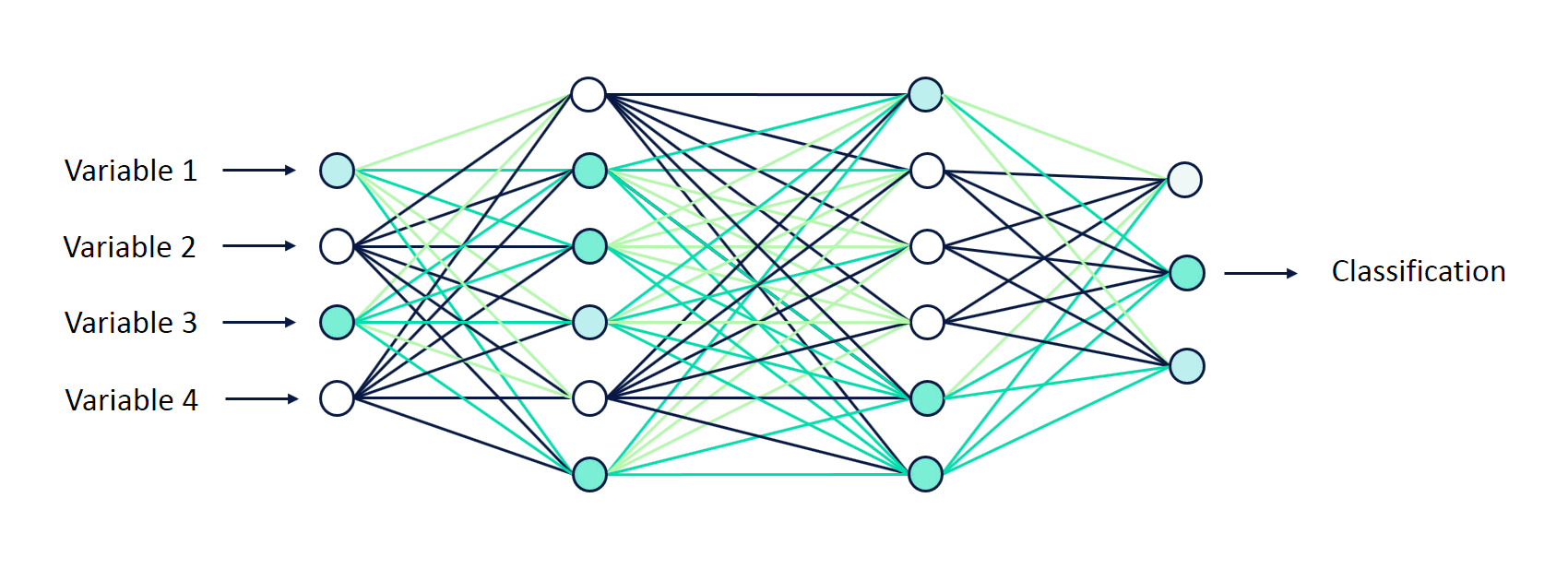
b. Convolutional Neural Networks (CNNs):
Explanation: CNNs are specialized neural networks for processing grid-like data, such as images. They use convolutional layers to automatically learn and extract features from images.
Application: CNNs are commonly used for image recognition tasks, object detection, and image generation.
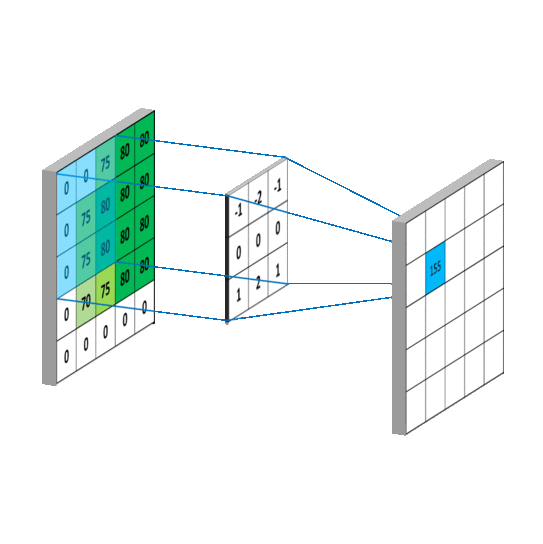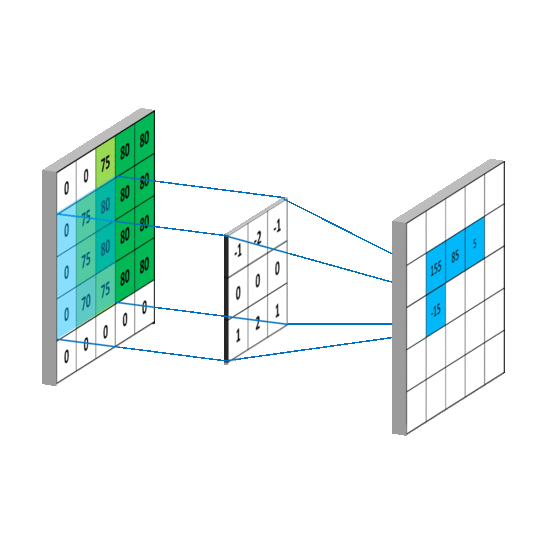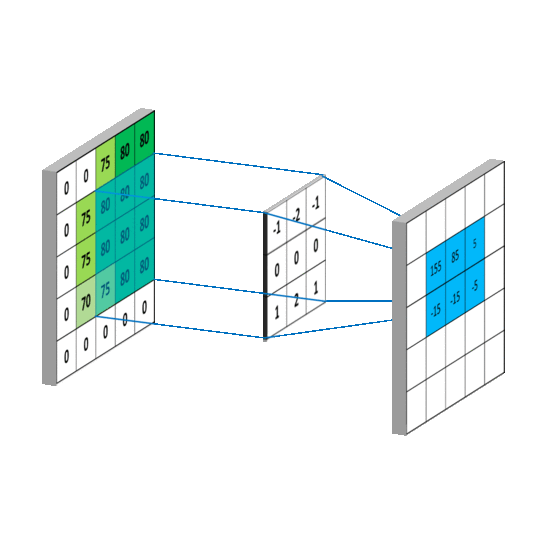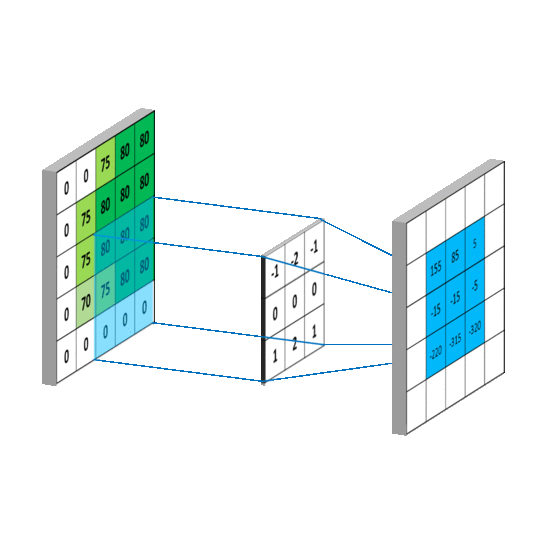
c. Recurrent Neural Networks (RNNs):
Explanation: RNNs are designed to work with sequential data, making them suitable for tasks involving time series, natural language processing, and speech recognition. They have loops that allow them to maintain a memory of previous inputs.
Application: RNNs are used in applications like machine translation, sentiment analysis, and speech generation.
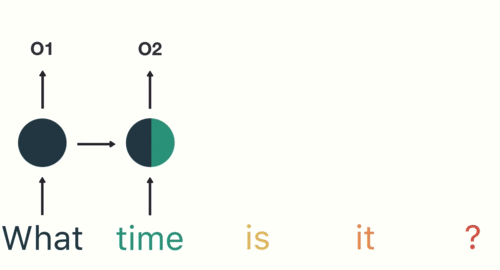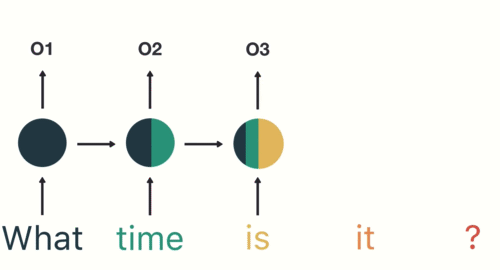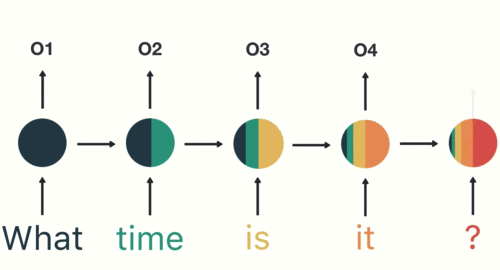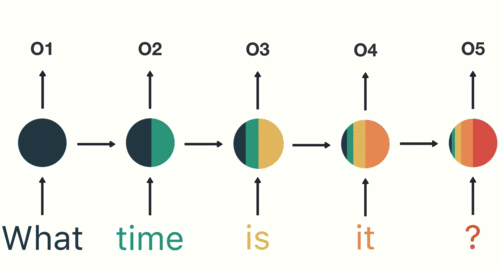
d. Frameworks:
Explanation: Deep Learning frameworks such as TensorFlow and PyTorch provide the tools and libraries to build, train, and deploy deep neural networks efficiently.
Application: These frameworks are used extensively in both research and industry for deep learning projects.

Evaluation Metrics
Evaluation is a crucial aspect of machine learning that involves assessing and measuring the performance of your machine learning models. Evaluation metrics help you determine how well your models are performing and whether they are making accurate predictions on your data.
Here's an explanation of some common evaluation metrics used in machine learning:
Accuracy: Accuracy is one of the most straightforward metrics. It measures the ratio of correctly predicted instances to the total number of instances in the dataset. While accuracy is easy to understand, it may not be suitable for imbalanced datasets, where one class significantly outnumbers the others.
Formula: (Number of Correct Predictions) / (Total Number of Predictions)
Precision: Precision is the ratio of correctly predicted positive instances to the total predicted positive instances. It helps you understand how many of the positive predictions made by your model were correct. Precision is essential when false positives are costly.
Formula: (True Positives) / (True Positives + False Positives)

Recall (Sensitivity): Recall, also known as sensitivity or true positive rate, is the ratio of correctly predicted positive instances to the total actual positive instances in the dataset. It helps you understand how many of the actual positive instances your model captured.
Formula: (True Positives) / (True Positives + False Negatives)
F1-Score: The F1-score is the harmonic mean of precision and recall. It provides a balanced measure of a model's performance, especially when you need to consider both false positives and false negatives.
Formula: 2 (Precision Recall) / (Precision + Recall)

ROC Curve (Receiver Operating Characteristic Curve): The ROC curve is a graphical representation of a classifier's performance across different threshold settings. It plots the true positive rate (recall) against the false positive rate for various threshold values. The area under the ROC curve (AUC) is also a common metric used to compare models.
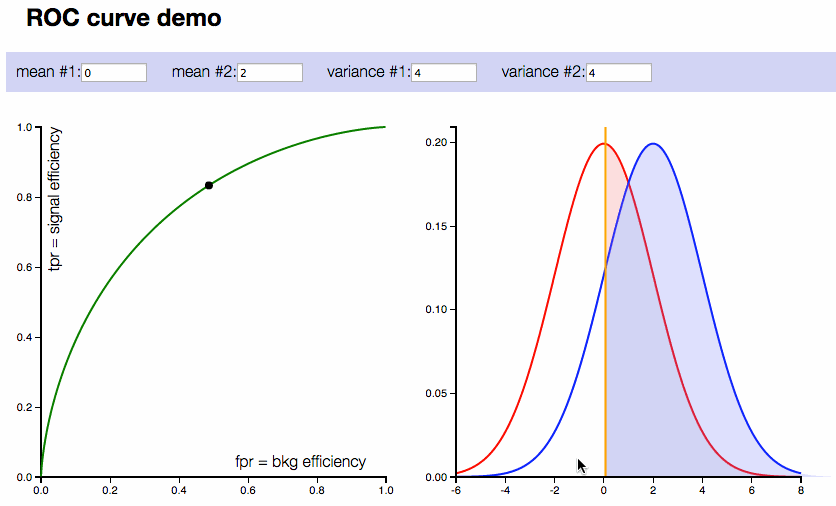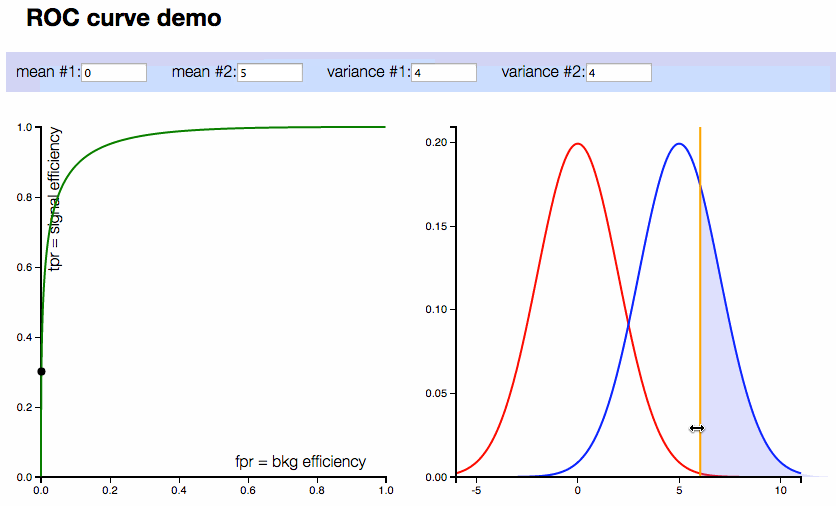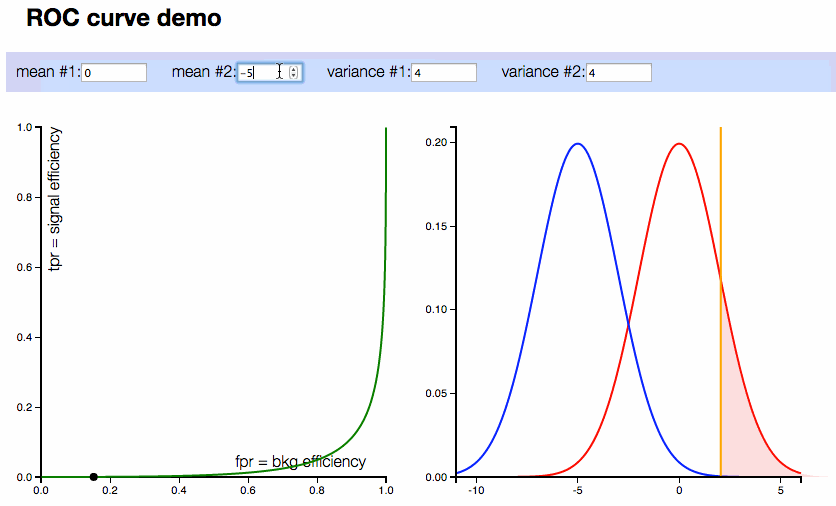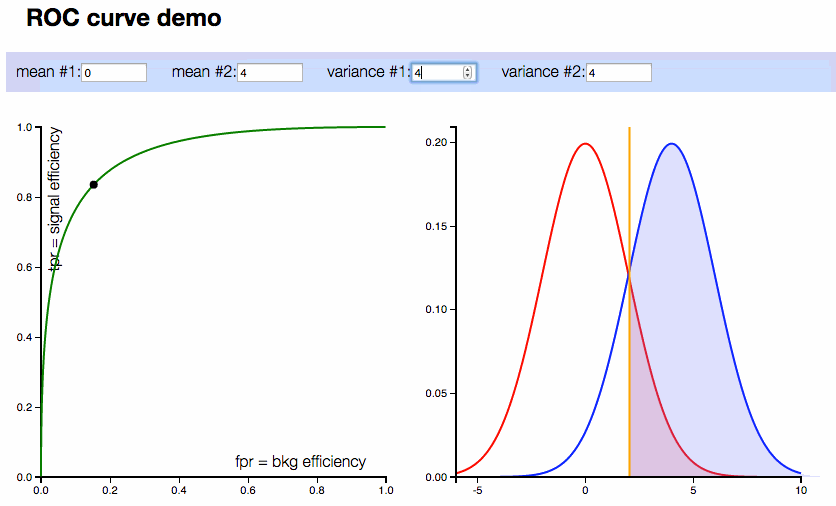
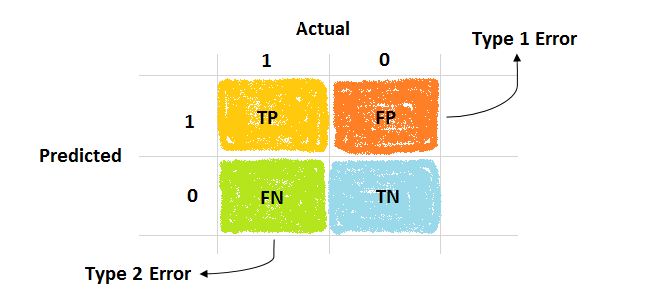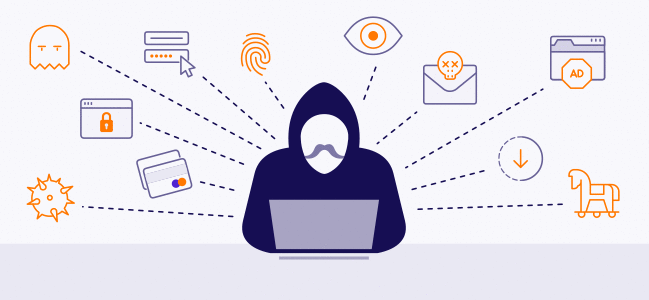
Confusion Matrix: A confusion matrix is a table that summarizes the performance of a classification algorithm. It provides a detailed view of the true positives, true negatives, false positives, and false negatives, making it easier to calculate metrics like precision and recall.
True Positives (TP): Correctly predicted positive instances.
True Negatives (TN): Correctly predicted negative instances.
False Positives (FP): Incorrectly predicted positive instances (Type I error).
False Negatives (FN): Incorrectly predicted negative instances (Type II error).
Understanding and using these evaluation metrics is essential in machine learning, as they help you assess the strengths and weaknesses of your models. Depending on your specific problem and business goals, you may prioritize different metrics.
Theoretical Concepts:
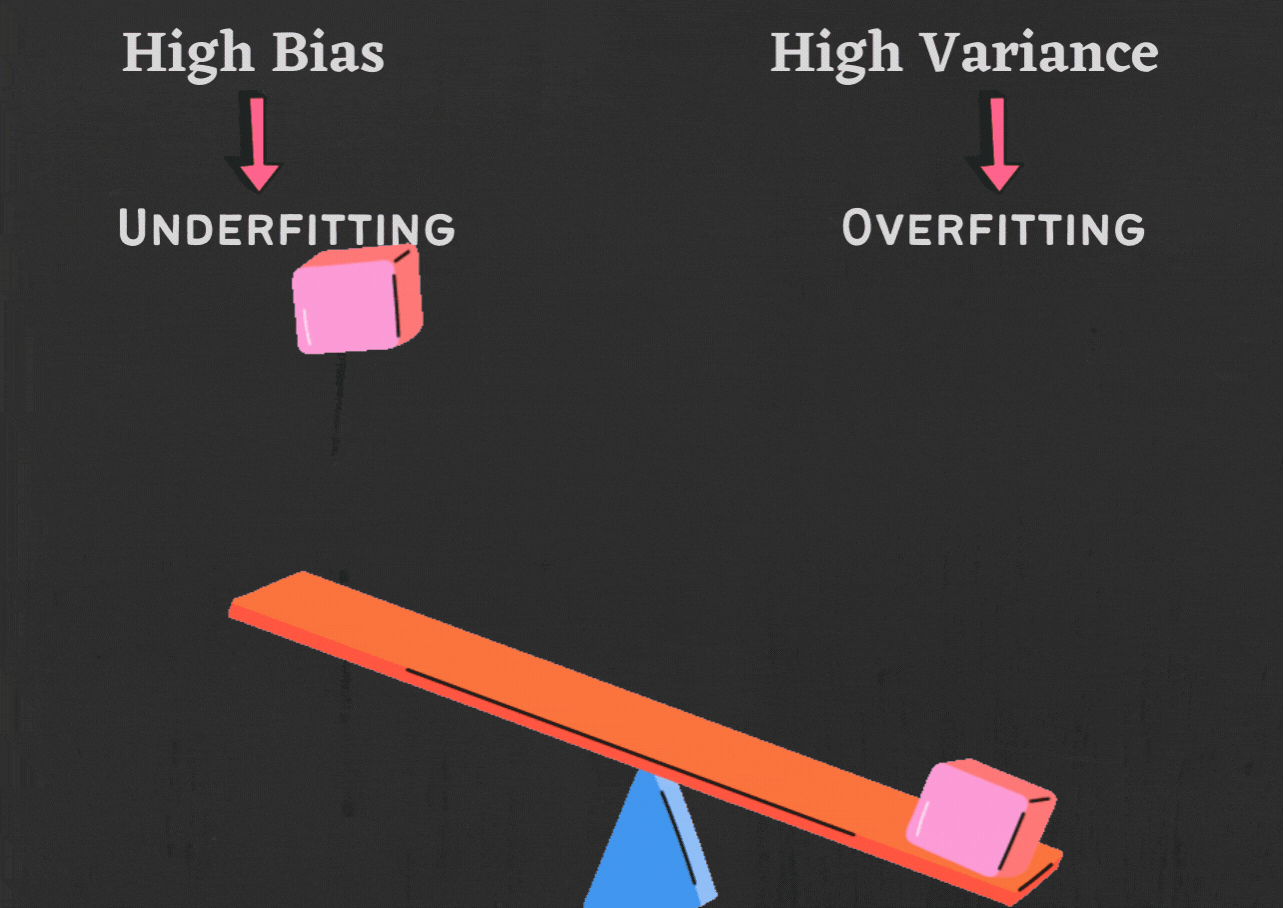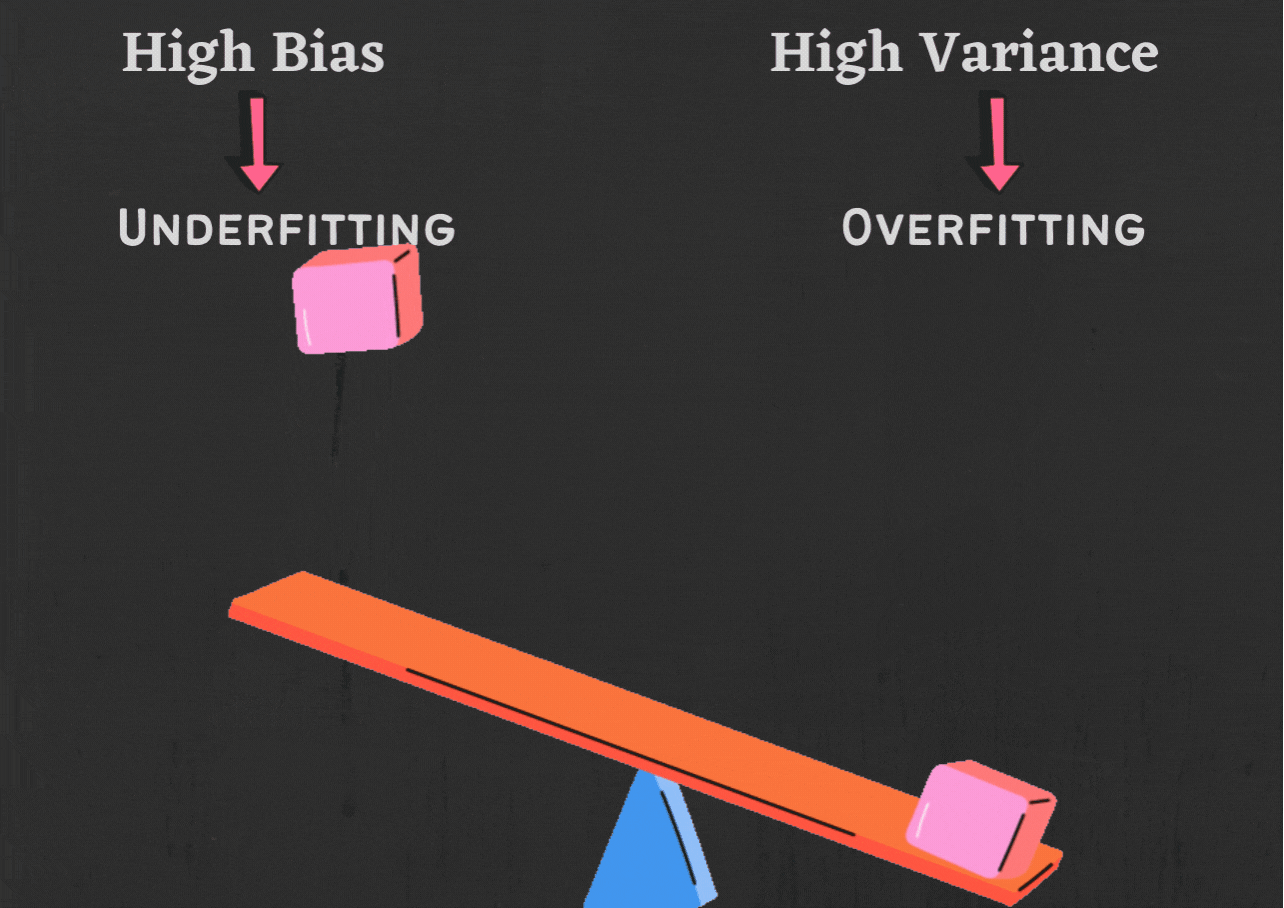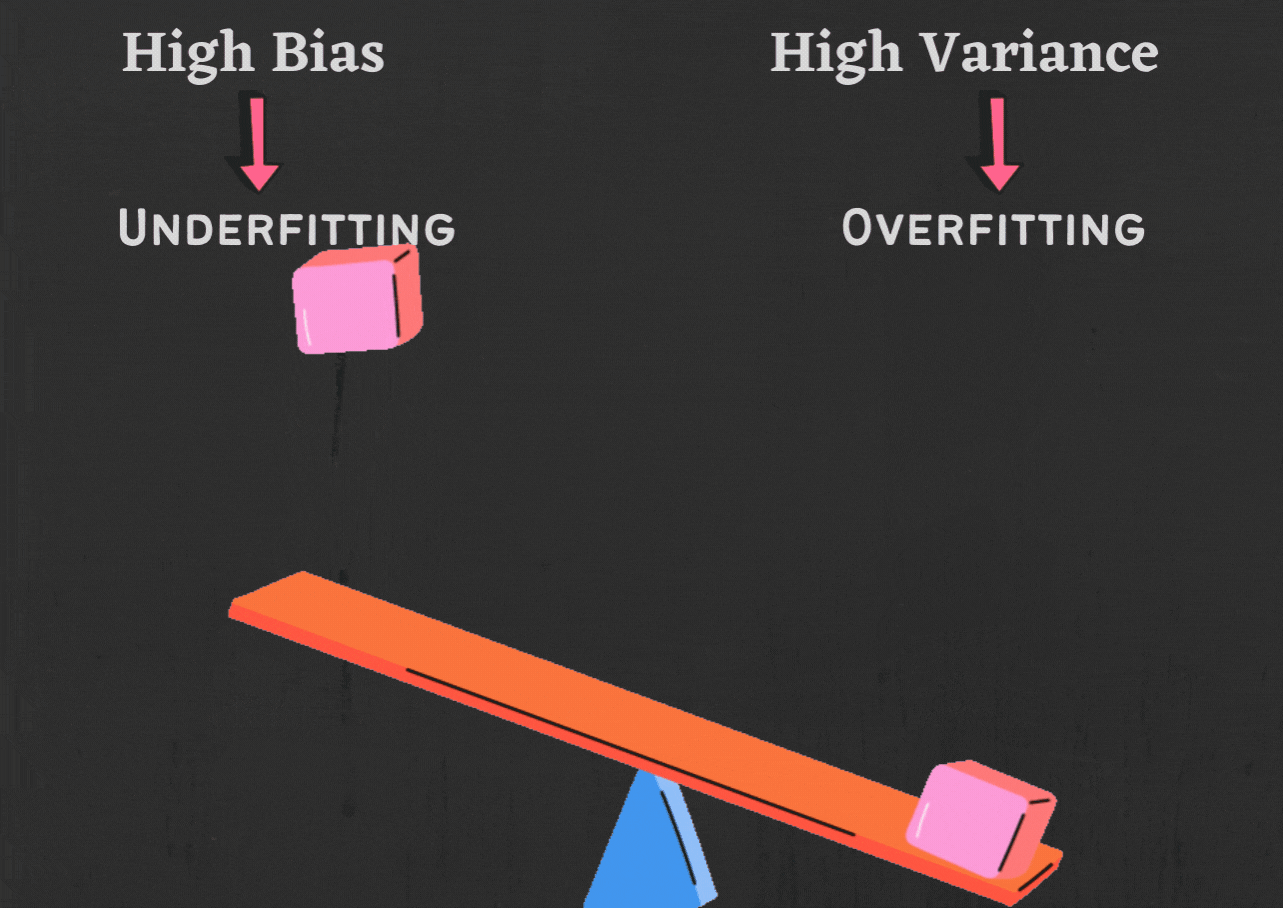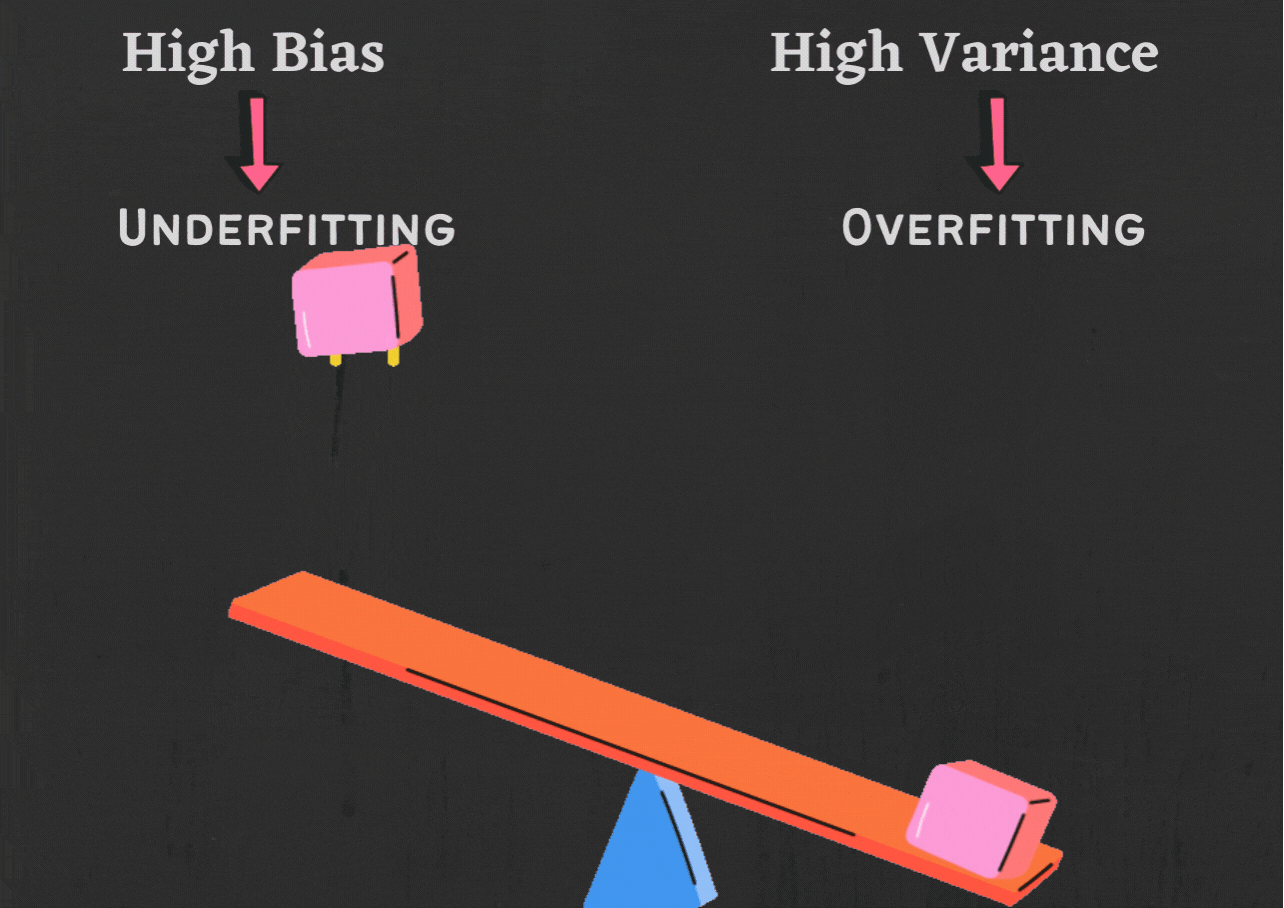
a. Bias-Variance Tradeoff:
The Bias-Variance tradeoff is a fundamental concept in machine learning. It refers to the balance between two types of errors that a model can make when predicting outcomes:
Bias: This error occurs when a model is too simplistic and fails to capture the underlying patterns in the data. High bias leads to underfitting, where the model is unable to learn from the data effectively.
Variance: This error arises when a model is too complex and overly sensitive to noise in the training data. High variance leads to overfitting, where the model learns the training data too well but fails to generalize to unseen data.
Achieving a balance between bias and variance is crucial. You want your model to be complex enough to capture important patterns but not so complex that it becomes overly sensitive to noise.
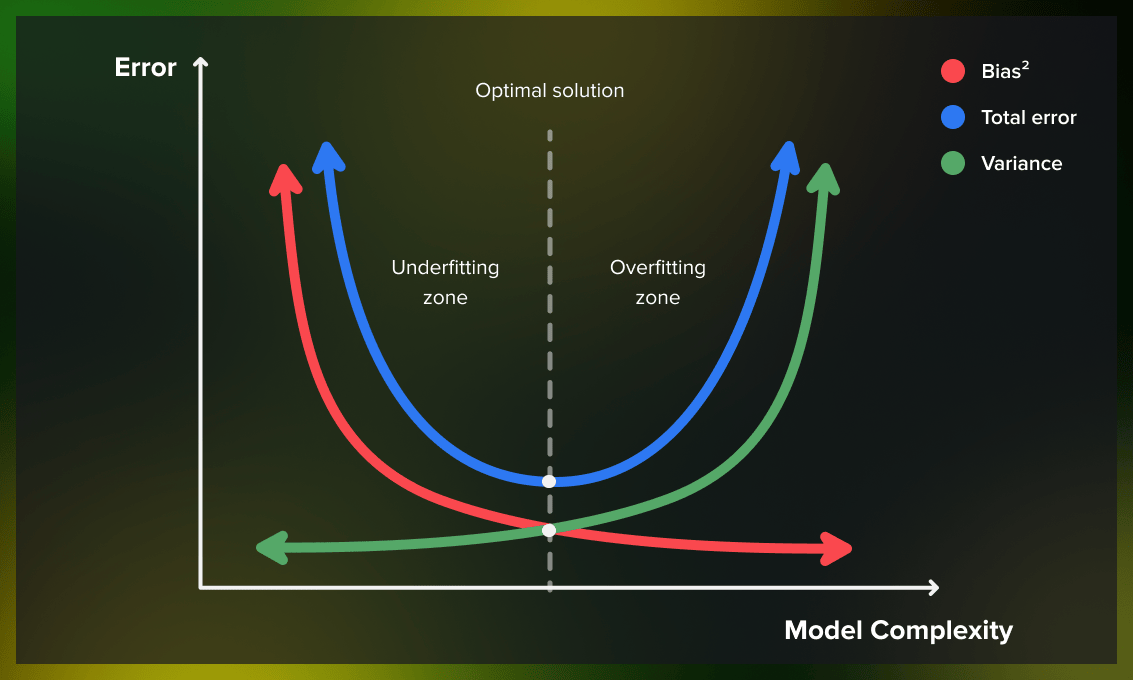
b. Overfitting and Underfitting:
Overfitting occurs when a model learns the training data too well, including the noise or random fluctuations in the data. This results in poor generalization to new, unseen data.
Underfitting happens when a model is too simple to capture the underlying patterns in the data, leading to poor performance on both the training and test datasets.
Striking the right balance between model complexity and data fitting is essential to avoid these issues.
c. Cross-Validation:
Cross-validation is a technique used to assess how well a model will generalize to unseen data. It involves dividing the dataset into multiple subsets, training the model on some of these subsets, and testing it on others.
Common cross-validation methods include k-fold cross-validation, where the data is split into k subsets (or "folds"), and each fold is used as both a testing and validation set.
Cross-validation helps in estimating a model's performance more accurately and identifying potential issues like overfitting.

d. Feature Engineering:
Feature engineering is the process of selecting, transforming, or creating relevant features (input variables) for your machine-learning model.
Choosing the right features can significantly impact a model's performance. It involves domain knowledge and creativity to extract meaningful information from the data.
Feature engineering may include techniques like one-hot encoding, scaling, and creating interaction features.
e. Ensemble Learning:
Ensemble learning involves combining the predictions of multiple machine learning models to improve overall performance.
Common ensemble methods include Bagging (e.g., Random Forests) and Boosting (e.g., AdaBoost and Gradient Boosting).
Ensemble methods can reduce overfitting, enhance model stability, and improve accuracy.
![Animation] Gentle Introduction to Ensemble Learning for Beginners - MLK - Machine Learning Knowledge](https://machinelearningknowledge.ai/wp-content/uploads/2019/12/Ensemble-Learning-Intuition.gif)
Understanding these theoretical concepts is essential for effectively designing, training, and evaluating machine learning models. It enables you to make informed decisions about model selection, hyperparameter tuning, and data preprocessing, ultimately leading to better results in real-world applications.
Practical Experience
Put your learning into action by working on real-world datasets and projects. Kaggle is an excellent platform for hands-on practice.
Apply various machine learning algorithms and techniques you've learned to solve practical problems.
Platforms like Kaggle provide a wealth of datasets and competitions to practice on.
Practical experience helps you develop problem-solving skills and a deeper understanding of how ML algorithms work in real scenarios.
It's a crucial step in becoming proficient in machine learning and gaining the confidence to tackle complex challenges.

Community and Forums
In the journey of learning Machine Learning, you're not alone. There are vibrant online communities and forums where you can connect with like-minded individuals, seek advice, and collaborate on projects. Websites like GitHub, Reddit, and Stack Overflow are excellent places to engage with experts, share your experiences, and get answers to your questions. These communities can be valuable sources of knowledge, inspiration, and support as you progress in your machine-learning journey. So, don't hesitate to join these platforms and tap into the collective wisdom of the ML community.

Stay Updated
ML is a rapidly evolving field. To remain relevant and excel in ML, it's crucial to stay updated with the latest developments. This involves:
Reading Research Papers: Regularly read research papers and publications from ML conferences and journals to stay informed about cutting-edge techniques and breakthroughs.
Following Industry Trends: Keep an eye on industry trends and how ML is being applied across different domains. Understanding real-world applications can inspire new ideas and projects.
Engaging with the Community: Participate in online ML communities, forums, and discussion platforms. Networking with peers and experts can provide valuable insights and support.
Taking Advanced Courses: Consider enrolling in advanced ML courses or specialized workshops to deepen your knowledge in specific areas of interest.
Experimenting: Continuously experiment with new models, algorithms, and datasets. Hands-on experience is a great way to understand the practical implications of ML advancements.

Conclusion
Machine Learning is an exciting field that holds immense potential. As a beginner, patience and consistent practice are key. Don't be discouraged by challenges; they are part of the learning process. With dedication and a solid foundation, you'll be well on your way to becoming a proficient machine learning practitioner. Happy learning!

Congratulations on making it to the end of this blog!
I hope this blog will help you kickstart your journey in Machine learning as a beginner. Feel free to drop your feedback in the comments.

You might not see me again, so why not follow instead : )




